De vez en cuando, los creacionistas acusan a la evolución de que carece de utilidad como teoría científica porque no produce beneficios prácticos y no tiene relevancia en la vida diaria. Sin embargo, tan sólo la evidencia de la biología demuestra que esta afirmación es falsa. Hay numerosos fenómenos naturales para los que la evolución nos ofrece un sólido fundamento teórico. Por nombrar uno, el desarrollo observado de la resistencia -a los insecticidas en las plagas de cultivos, a los antibióticos en las bacterias, a la quimioterapia en las células cancerosas, y a los fármacos antiretrovirales en virus como el VIH- es una consecuencia abierta de las leyes de la mutación y la selección, y comprender estos principios nos ha ayudado a desarrollar estrategias para enfrentarnos a estos nocivos organismos. El postulado evolutivo de la descendencia común ha ayudado al desarrollo de nuevos medicamentos y técnicas, al proporcionar a los investigadores una buena idea de con qué organismos deben experimentar para obtener resultados que probablemente serán relevantes para los seres humanos. Finalmente, el hombre ha utilizado con grandes resultados el principio de cría selectiva para crear organismos personalizados, distintos a cualquiera que se pueda encontrar en la naturaleza, para beneficio propio. El ejemplo canónico, por supuesto, es la diversidad de variedades de perros domésticos (razas tan diversas como los bulldogs, chihuahuas y dachshunds han sido producidas a partir de lobos en sólo unos pocos miles de años), pero ejemplos menos conocidos incluyen al maíz cultivado (muy diferente de sus parientes salvajes, que carecen de las familiares ``orejas'' del maíz cultivado), a los peces de colores (como los perros, hemos criado variedades cuyo aspecto es drásticamente distinto al del tipo salvaje), y a las vacas lecheras (con ubres inmensas, mucho mayores que las necesarias para alimentar a una cría).
Los críticos pueden argumentar que los creacionistas pueden explicar estas cosas sin recurrir a la evolución. Por ejemplo, a menudo los creacionistas explican el desarrollo de la resistencia a los agentes antibióticos en las bacterias, o los cambios forjados en los animales domésticos por selección artificial, asumiendo que Dios decidió crear a los organismos en grupos fijos, llamados ``tipos'' o baramins. Aunque la microevolución natural o la selección artificial dirigida por humanos pueden producir diferentes variedades dentro de los ``tipo-perro'', ``tipo-vaca'' o ``tipo-bacteria'' (!) creados originalmente, ninguna cantidad de tiempo o cambio genético puede transformar un ``tipo'' en otro. Sin embargo, nunca se explica cómo determinan los creacionistas lo que es un ``tipo'', o qué mecanismo impide a los seres vivos evolucionar más allá de sus límites.
Pero en las últimas décadas, el continuo avance de la tecnología moderna ha producido algo nuevo. Ahora la evolución está produciendo beneficios prácticos en un campo muy distinto y, esta vez, los creacionistas no pueden afirmar que su explicación se adapte a los hechos igual de bien. Este campo es la informática, y los beneficios provienen de una estrategia de programación llamada algoritmos genéticos. Este ensayo explicará qué son los algoritmos genéticos y mostrará de qué manera son relevantes en el debate evolución/creacionismo.
Expuesto concisamente, un algoritmo genético (o AG para abreviar) es una técnica de programación que imita a la evolución biológica como estrategia para resolver problemas. Dado un problema específico a resolver, la entrada del AG es un conjunto de soluciones potenciales a ese problema, codificadas de alguna manera, y una métrica llamada función de aptitud que permite evaluar cuantitativamente a cada candidata. Estas candidatas pueden ser soluciones que ya se sabe que funcionan, con el objetivo de que el AG las mejore, pero se suelen generar aleatoriamente.
Luego el AG evalúa cada candidata de acuerdo con la función de aptitud. En un acervo de candidatas generadas aleatoriamente, por supuesto, la mayoría no funcionarán en absoluto, y serán eliminadas. Sin embargo, por puro azar, unas pocas pueden ser prometedoras -pueden mostrar actividad, aunque sólo sea actividad débil e imperfecta, hacia la solución del problema.
Estas candidatas prometedoras se conservan y se les permite reproducirse. Se realizan múltiples copias de ellas, pero las copias no son perfectas; se introducen cambios aleatorios durante el proceso de copia. Luego, esta descendencia digital prosigue con la siguiente generación, formando un nuevo acervo de soluciones candidatas, y son sometidas a una ronda de evaluación de aptitud. Las candidatas que han empeorado o no han mejorado con los cambios en su código son eliminadas de nuevo; pero, de nuevo, por puro azar, las variaciones aleatorias introducidas en la población pueden haber mejorado a algunos individuos, convirtiéndolos en mejores soluciones del problema, más completas o más eficientes. De nuevo, se selecionan y copian estos individuos vencedores hacia la siguiente generación con cambios aleatorios, y el proceso se repite. Las expectativas son que la aptitud media de la población se incrementará en cada ronda y, por tanto, repitiendo este proceso cientos o miles de rondas, pueden descubrirse soluciones muy buenas del problema.
Aunque a algunos les puede parecer asombroso y antiintuitivo, los algoritmos genéticos han demostrado ser una estrategia enormemente poderosa y exitosa para resolver problemas, demostrando de manera espectacular el poder de los principios evolutivos. Se han utilizado algoritmos genéticos en una amplia variedad de campos para desarrollar soluciones a problemas tan difíciles o más difíciles que los abordados por los diseñadores humanos. Además, las soluciones que consiguen son a menudo más eficientes, más elegantes o más complejas que nada que un ingeniero humano produciría. ¡En algunos casos, los algoritmos genéticos han producido soluciones que dejan perplejos a los programadores que escribieron los algoritmos en primera instancia!
Antes de que un algoritmo genético pueda ponerse a trabajar en un problema, se necesita un método para codificar las soluciones potenciales del problema de forma que una computadora pueda procesarlas. Un enfoque común es codificar las soluciones como cadenas binarias: secuencias de 1s y 0s, donde el dígito de cada posición representa el valor de algún aspecto de la solución. Otro método similar consiste en codificar las soluciones como cadenas de enteros o números decimales, donde cada posición, de nuevo, representa algún aspecto particular de la solución. Este método permite una mayor precisión y complejidad que el método comparativamente restringido de utilizar sólo números binarios, y a menudo ``está intuitivamente más cerca del espacio de problemas'' (Fleming y Purshouse 2002[3], p 1.228).
Esta técnica se utilizó, por ejemplo, en el trabajo de Steffen Schulze-Kremer, que escribió un algoritmo genético para predecir la estructura tridimensional de una proteína, basándose en la secuencia de aminoácidos que la componen (Mitchell 1996[47], p. 62). El AG de Schulze-Kremer utilizaba números reales para representar los famosos ``ángulos de torsión'' entre los enlaces peptídicos que conectan a los aminoácidos. (Una proteína está formada por una secuencia de bloques básicos llamados aminoácidos, que se conectan como los eslabones de una cadena. Una vez que todos los aminoácidos están enlazados, la proteína se dobla formando una compleja estructura tridimensional, basada en cuáles aminoácidos se atraen entre ellos y cuáles se repelen. La forma de una proteína determina su función). Los algoritmos genéticos para entrenar a las redes neuronales también utilizan a menudo este método de codificación.
Un tercer método consiste en representar a los individuos de un AG como cadenas de letras, donde cada letra, de nuevo, representa un aspecto específico de la solución. Un ejemplo de esta técnica es el método basado en ``codificación gramática'' de Hiroaki Kitano, en el que a un AG se le encargó la tarea de evolucionar un sencillo conjunto de reglas llamadas gramática libre de contexto, que a su vez se utilizaban para generar redes neuronales para una variedad de problemas (Mitchell 1996[47], p. 74).
La virtud de estos tres métodos es que facilitan la definición de operadores que causen los cambios aleatorios en las candidatas seleccionadas: cambiar un 0 por un 1 o viceversa, sumar o restar al valor de un número una cantidad elegida al azar, o cambiar una letra por otra. (Ver la sección sobre los métodos de cambio para más detalles acerca de los operadores genéticos). Otra estrategia, desarrollada principalmente por John Koza, de la Universidad de Stanford, y denominada programación genética, representa a los programas como estructuras de datos ramificadas llamadas árboles (Koza et al. 2003[42], p. 35). En este método, los cambios aleatorios pueden generarse cambiado el operador o alterando el valor de un cierto nodo del árbol, o sustituyendo un subárbol por otro.
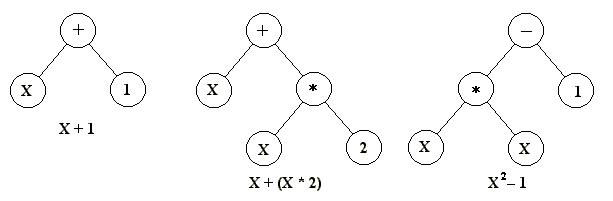
|
Es importante señalar que los algoritmos evolutivos no necesitan representar las soluciones candidatas como cadenas de datos de una longitud fija. Algunos las representan de esta manera, pero otros no; por ejemplo, la ``codificación gramatical'' de Kitano, explicada arriba, puede escalarse eficientemente para crear redes neuronales grandes y complejas, y los árboles de programación genética de Koza pueden crecer arbitrariamente tanto como sea necesario para resolver cualquier problema que se les pida.
Un algoritmo genético puede utilizar muchas técnicas diferentes para seleccionar a los individuos que deben copiarse hacia la siguiente generación, pero abajo se listan algunos de los más comunes. Algunos de estos métodos son mutuamente exclusivos, pero otros pueden utilizarse en combinación, algo que se hace a menudo.
Una vez que la selección ha elegido a los individuos aptos, éstos deben ser alterados aleatoriamente con la esperanza de mejorar su aptitud para la siguiente generación. Existen dos estrategias básicas para llevar esto a cabo. La primera y más sencilla se llama mutación. Al igual que una mutación en los seres vivos cambia un gen por otro, una mutación en un algoritmo genético también causa pequeñas alteraciones en puntos concretos del código de un idividuo.
El segundo método se llama cruzamiento, e implica elegir a dos individuos para que intercambien segmentos de su código, produciendo una ``descendencia'' artificial cuyos individuos son combinaciones de sus padres. Este proceso pretende simular el proceso análogo de la recombinación que se da en los cromosomas durante la reproducción sexual. Las formas comunes de cruzamiento incluyen al cruzamiento de un punto, en el que se establece un punto de intercambio en un lugar aleatorio del genoma de los dos individuos, y uno de los individuos contribuye todo su código anterior a ese punto y el otro individuo contribuye todo su código a partir de ese punto para producir una descendencia, y al cruzamiento uniforme, en el que el valor de una posición dada en el genoma de la descendencia corresponde al valor en esa posición del genoma de uno de los padres o al valor en esa posición del genoma del otro padre, elegido con un 50% de probabilidad.
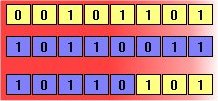

|
Con el auge de la informática de inteligencia artificial y el desarrollo de los métodos heurísticos, han emergido otras técnicas de resolución computerizada de problemas que en algunos aspectos son similares a los algoritmos genéticos. Esta sección explica algunas de estas técnicas, en qué se parecen a los AGs y en qué se diferencian.
Una red neuronal es un método de resolución de problemas basado en un modelo informático de la manera en que están conectadas las neuronas del cerebro. Una red neuronal consiste en capas de unidades procesadoras, llamadas nodos, unidas por conexiones direccionales: una capa de entrada, una capa de salida y cero o más capas ocultas enmedio. Se le presenta un patrón inicial de entrada a la capa de entrada, y luego los nodos que se estimulan transmiten una señal a los nodos de la siguiente capa a la que están conectados. Si la suma de todas las entradas que entran en una de estas neuronas virtuales es mayor que el famoso umbral de activación de la neurona, esa neurona se activa, y transmite su propia señal a las neuronas de la siguiente capa. El patrón de activación, por tanto, se propaga hacia delante hasta que alcanza a la capa de salida, donde es devuelto como solución a la entrada presentada. Al igual que en el sistema nervioso de los organismos biológicos, las redes neuronales aprenden y afinan su rendimiento a lo largo del tiempo, mediante la repetición de rondas en las que se ajustan sus umbrales, hasta que la salida real coincide con la salida deseada para cualquier entrada dada. Este proceso puede ser supervisado por un experimentador humano, o puede correr automáticamente utilizando un algoritmo de aprendizaje (Mitchell 1996[47], p. 52). Se han utilizado algoritmos genéticos para construir y entrenar a redes neuronales.
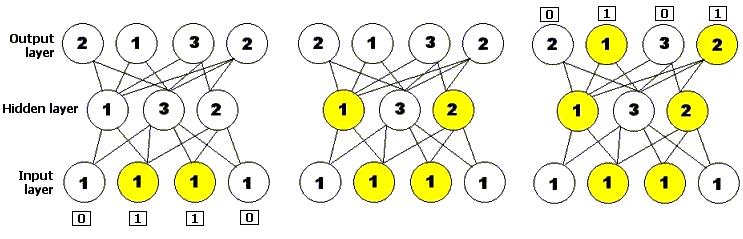
|
Similares a los algoritmos genéticos, aunque más sistemáticos y menos aleatorios. Un algoritmo de ascenso a colina comienza con una solución al problema a mano, normalmente elegida al azar. Luego, la cadena se muta, y si la mutación proporciona una solución con mayor aptitud que la solución anterior, se conserva la nueva solución; en caso contrario, se conserva la solución actual. Luego el algoritmo se repite hasta que no se pueda encontrar una mutación que provoque un incremento en la aptitud de la solución actual, y esta solución se devuelve como resultado (Koza et al. 2003[42], p. 59). (Para entender de dónde viene el nombre de esta técnica, imagine que el espacio de todas las soluciones posibles de un cierto problema se representa como un paisaje tridimensional. Un conjunto de coordenadas en ese paisaje representa una solución particular. Las soluciones mejores están a mayor altitud, formando colinas y picos; las que son peores están a menor altitud, formando valles. Un ``trepacolinas'' es, por tanto, un algoritmo que comienza en un punto dado del paisaje y se mueve inexorablemente colina arriba). El algoritmo de ascenso a colina es lo que se conoce como algoritmo voraz, lo que significa que siempre hace la mejor elección disponible en cada paso, con la esperanza de que de esta manera se puede obtener el mejor resultado global. En contraste, los métodos como los algoritmos genéticos y el recocido simulado, discutido abajo, no son voraces; a veces, estos métodos hacen elecciones menos óptimas al principio con la esperanza de que conducirán hacia una solución mejor más adelante.
Otra técnica de optimización similar a los algoritmos evolutivos se conoce como recocido simulado. La idea toma prestado su nombre del proceso industrial en el que un material se calienta por encima de su punto de fusión y luego se enfría gradualmente para eliminar defectos en su estructura cristalina, produciendo un entramado de átomos más estable y regular (Haupt y Haupt 1998[34], p. 16). En el recocido simulado, como en los algoritmos genéticos, existe una función de aptitud que define un paisaje adaptativo; sin embargo, en lugar de una población de candidatas como en los AGs, sólo existe una solución candidata. El recocido simulado también añade el concepto de ``temperatura'', una cantidad numérica global que disminuye gradualmente en el tiempo. En cada paso del algoritmo, la solución muta (lo que es equivalente a moverse hacia un punto adyacente en el paisaje adaptativo). Luego, la aptitud de la nueva solución se compara con la aptitud de la solución anterior; si es mayor, se conserva la nueva solución. En caso contrario, el algoritmo toma la decisión de conservarla o descartarla en base a la temperatura. Si la temperatura es alta, como lo es al principio, pueden conservarse incluso cambios que causan decrementos significativos en la aptitud, y utilizarse como base para la siguiente ronda del algoritmo, pero al ir disminuyendo la temperatura, el algoritmo se va haciendo más y más propenso a aceptar sólo los cambios que aumentan la aptitud. Finalmente, la temperatura alzanca el cero y el sistema se ``congela''; cualquiera que sea la configuración que exista en ese punto se convierte en la solución. El recocido simulado tiene a menudo aplicaciones en la ingeniería del diseño, como determinar la disposición física de los componentes en un chip informático (Kirkpatrick, Gelatt y Vecchi 1983[40]).
Los primeros ejemplos de lo que hoy podríamos llamar algoritmos genéticos aparecieron a finales de los 50 y principios de los 60, programados en computadoras por biólogos evolutivos que buscaban explícitamente realizar modelos de aspectos de la evolución natural. A ninguno de ellos se le ocurrió que esta estrategia podría aplicarse de manera más general a los problemas artificiales, pero ese reconocimiento no tardaría en llegar: ``La computación evolutiva estaba definitivamente en el aire en los días formativos de la computadora electrónica'' (Mitchell 1996[47], p.2). En 1962, investigadores como G.E.P. Box, G.J. Friedman, W.W. Bledsoe y H.J. Bremermann habían desarrollado independientemente algoritmos inspirados en la evolución para optimización de funciones y aprendizaje automático, pero sus trabajos generaron poca reacción. En 1965 surgió un desarrollo más exitoso, cuando Ingo Rechenberg, entonces de la Universidad Técnica de Berlín, introdujo una técnica que llamó estrategia evolutiva, aunque se parecía más a los trepacolinas que a los algoritmos genéticos. En esta técnica no había población ni cruzamiento; un padre mutaba para producir un descendiente, y se conservaba el mejor de los dos, convirtiéndose en el padre de la siguiente ronda de mutación (Haupt y Haupt 1998[34], p.146). Versiones posteriores introdujeron la idea de población. Las estrategias evolutivas todavía se emplean hoy en día por ingenieros y científicos, sobre todo en Alemania.
El siguiente desarrollo importante en el campo vino en 1966, cuando L.J. Fogel, A.J. Owens y M.J. Walsh introdujeron en América una técnica que llamaron programación evolutiva. En este método, las soluciones candidatas para los problemas se representaban como máquinas de estado finito sencillas; al igual que en la estrategia evolutiva de Rechenberg, su algoritmo funcionaba mutando aleatoriamente una de estas máquinas simuladas y conservando la mejor de las dos (Mitchell 1996[47], p.2; Goldberg 1989[29], p.105). También al igual que las estrategias evolutivas, hoy en día existe una formulación más amplia de la técnica de programación evolutiva que todavía es un área de investigación en curso. Sin embargo, lo que todavía faltaba en estas dos metodologías era el reconocimiento de la importancia del cruzamiento.
En una fecha tan temprana como 1962, el trabajo de John Holland sobre sistemas adaptativos estableció las bases para desarrollos posteriores; y lo que es más importante, Holland fue también el primero en proponer explícitamente el cruzamiento y otros operadores de recombinación. Sin embargo, el trabajo fundamental en el campo de los algoritmos genéticos apareció en 1975, con la publicación del libro ``Adaptación en Sistemas Naturales y Artificiales''. Basado en investigaciones y papers anteriores del propio Holland y de colegas de la Universidad de Michigan, este libro fue el primero en presentar sistemática y rigurosamente el concepto de sistemas digitales adaptativos utilizando la mutación, la selección y el cruzamiento, simulando el proceso de la evolución biológica como estrategia para resolver problemas. El libro también intentó colocar los algoritmos genéticos sobre una base teórica firme introduciendo el concepto de esquema (Mitchell 1996[47], p.3; Haupt y Haupt 1998[34], p.147). Ese mismo año, la importante tesis de Kenneth De Jong estableció el potencial de los AGs demostrando que podían desenvolverse bien en una gran variedad de funciones de prueba, incluyendo paisajes de búsqueda ruidosos, discontinuos y multimodales (Goldberg 1989[29], p.107).
Estos trabajos fundacionales establecieron un interés más generalizado en la computación evolutiva. Entre principios y mediados de los 80, los algoritmos genéticos se estaban aplicando en una amplia variedad de áreas, desde problemas matemáticos abstractos como el ``problema de la mochila'' (bin-packing) y la coloración de grafos hasta asuntos tangibles de ingeniería como el control de flujo en una línea de ensamble, reconocimiento y clasificación de patrones y optimización estructural (Goldberg 1989[29], p.128).
Al principio, estas aplicaciones eran principalmente teóricas. Sin embargo, al seguir proliferando la investigación, los algoritmos genéticos migraron hacia el sector comercial, al cobrar importancia con el crecimiento exponencial de la potencia de computación y el desarrollo de Internet. Hoy en día, la computación evolutiva es un campo floreciente, y los algoritmos genéticos están ``resolviendo problemas de interés cotidiano'' (Haupt y Haupt 1998[34], p.147) en áreas de estudio tan diversas como la predicción en la bolsa y la planificación de la cartera de valores, ingeniería aeroespacial, diseño de microchips, bioquímica y biología molecular, y diseño de horarios en aeropuertos y líneas de montaje. La potencia de la evolución ha tocado virtualmente cualquier campo que uno pueda nombrar, modelando invisiblemente el mundo que nos rodea de incontables maneras, y siguen descubriéndose nuevos usos mientras la investigación sigue su curso. Y en el corazón de todo esto se halla nada más que la simple y poderosa idea de Charles Darwin: que el azar en la variación, junto con la ley de la selección, es una técnica de resolución de problemas de inmenso poder y de aplicación casi ilimitada.
Aunque los algoritmos genéticos han demostrado su eficiencia y potencia como estrategia de resolución de problemas, no son la panacea. Los AGs tienen ciertas limitaciones; sin embargo, se demostrará que todas ellas pueden superarse y que ninguna de ellas afecta a la validez de la evolución biológica.
Mientras el poder de la evolución gana reconocimiento cada vez más generalizado, los algoritmos genéticos se utilizan para abordar una amplia variedad de problemas en un conjunto de campos sumamente diverso, demostrando claramente su capacidad y su potencial. Esta sección analizará algunos de los usos más notables en los que han tomado parte.
Sato et al. 2002[58] utilizaron algoritmos genéticos para diseñar una sala de conciertos con propiedades acústicas óptimas, maximizando la calidad del sonido para la audiencia, para el director y para los músicos del escenario. Esta tarea implica la optimización simultánea de múltiples variables. Comenzando con una sala con forma de caja de zapatos, el AG de los autores produjo dos soluciones no dominadas, ambas descritas como ``con forma de hoja'' (p. 526). Los autores afirman que estas soluciones tienen proporciones similares al Grosser Musikvereinsaal de Viena, el cual está considerado generalmente como una de las mejores -si no la mejor- salas de conciertos del mundo, en términos de propiedades acústicas.
Porto, Fogel y Fogel 1995[51] utilizaron programación evolutiva para adiestrar a redes neuronales para distinguir entre reflexiones sonoras desde distintos tipos de objetos: esferas metálicas hechas por el hombre, montañas submarinas, peces y plantas, y ruido aleatorio de fondo. Tras 500 generaciones, la mejor red neuronal que evolucionó tenía una probabilidad de clasificación correcta que iba desde el 94% al 98%, y una probabilidad de clasificación errónea entre un 7,4% y un 1,5%, que son ``probabilidades razonables de detección y falsa alarma'' (p. 21). Esta red evolucionada igualó las prestaciones de otra red desarrollada mediante recocido simulado, y superó consistentemente a redes entrenadas mediante propagación hacia atrás, las cuales ``se atascaban repetidamente en conjuntos de pesos subóptimos que no producían resultados satisfactorios'' (p. 21). En contraste, ambos métodos estocásticos demostraron su capacidad para superar estos óptimos locales y producir redes más pequeñas, efectivas y robustas; pero los autores sugieren que el algoritmo evolutivo, a diferencia del recocido simulado, opera sobre una población, y por tanto se beneficia de la información global sobre el espacio de búsqueda, conduciendo potencialmente hacia un rendimiento mayor a la larga.
Tang et al. 1996[62] analizan los usos de los algoritmos genéticos en el campo de la acústica y el procesamiento de señales. Un área de interés particular incluye el uso de AGs para diseñar sistemas de Control Activo de Ruido (CAR), que eliminan el sonido no deseado produciendo ondas sonoras que interfieren destructivamente con el ruido. Esto es un problema de múltiples objetivos que requiere el control y la colocación precisa de múltiples altavoces; los AGs se han utilizado en estos sistemas tanto para diseñar los controladores como para encontrar la colocación óptima de los altavoces, dando como resultado una ``atenuación efectiva del ruido'' (p. 33) en pruebas experimentales.
Obayashi et al. 2000[49] utilizaron un algoritmo genético de múltiples objetivos para diseñar la forma del ala de un avión supersónico. Hay tres consideraciones principales que determinan la configuración del ala -minimizar la resistencia aerodinámica a velocidades de vuelo supersónicas, minimizar la resistencia a velocidades subsónicas y minimizar la carga aerodinámica (la fuerza que tiende a doblar el ala). Estos objetivos son mutuamente exclusivos, y optimizarlos todos simultáneamente requiere realizar contrapartidas.
El cromosoma de este problema es una cadena de 66 números reales, cada uno de los cuales corresponde a un aspecto específico del ala: su forma, su grosor, su torsión, etcétera. Se simuló una evolución con selección elitista durante 70 generaciones, con un tamaño de población de 64 individuos. Al final de este proceso había varios individuos paretianos, cada uno representando una solución no dominada del problema. El artículo comenta que estos individuos ganadores tenían características ``físicamente razonables'', señalando la validez de la técnica de optimización (p. 186). Para evaluar mejor la calidad de las soluciones, las seis mejores fueron comparadas con un diseño de ala supersónica producido por el Equipo de Diseño SST del Laboratorio Aeroespacial Nacional de Japón. Las seis fueron competitivas, con valores de resistencia y carga aproximadamente iguales o menores a los del ala diseñada por humanos; en particular, una de las soluciones evolucionadas superó al diseño del LAN en los tres objetivos. Los autores señalan que las soluciones del AG son similares a un diseño llamado ``ala flecha'', sugerido por primera vez a finales de los años 50, pero que finalmente fue abandonado en favor del diseño más convencional con forma de delta.
En un artículo posterior (Sasaki et al. 2001[57]), los autores repitieron el experimento añadiendo un cuarto objetivo, a saber, minimizar el momento de torsión (un conocido problema en los diseños de alas flecha en el vuelo supersónico). También se añadieron puntos de control adicionales para el grosor al conjunto de variables de diseño. Tras 75 generaciones de evolución, se compararon dos de las mejores soluciones paretianas con el diseño de ala que el Laboratorio Aeroespacial Nacional japonés realizó para el avión supersónico experimental NEXST-1. Se descubrió que ambos diseños (además de un diseño óptimo de la simulación anterior, explicada arriba) eran físicamente razonables y superiores al diseño del LAN en los cuatro objetivos.
Williams, Crossley y Lang 2001[64] aplicaron algoritmos genéticos a la tarea de situar órbitas de satélites para minimizar los apagones de cobertura. Mientras la tecnología de telecomunicaciones sigue progresando, los humanos somos cada vez más dependientes de las funciones vitales que realizan los satélites en órbita alrededor de la Tierra, y uno de los problemas con los que se enfrentan los ingenieros es el diseño de las trayectorias orbitales. Los satélites que se encuentran en una órbita terrestre alta, a unos 35.000 kilómetros de altitud, pueden ver amplias secciones del planeta al mismo tiempo y estar en contacto con las estaciones terrestres, pero son mucho más caros de lanzar y más vulnerables a las radiaciones cósmicas. Es más económico colocar satélites en órbitas bajas, en algunos casos a sólo unos pocos cientos de kilómetros; pero, a causa de la curvatura de la Tierra, es inevitable que estos satélites pierdan durante un tiempo la línea de visión con los receptores terrestres, y por lo tanto se vuelven inútiles. Incluso las constelaciones de varios satélites tienen apagones ineludibles y pérdidas de cobertura por esta razón. El reto consiste en colocar las órbitas de los satélites para minimizar este tiempo muerto. Esto es un problema multi-objetivo que implica la minimización de el tiempo medio de apagón para todas las localizaciones y el tiempo máximo de apagón para cada una de las localizaciones; en la práctica, estos objetivos resultan ser mutuamente exclusivos.
Cuando se utilizó el AG en este problema, los resultados que evolucionaron para constelaciones de tres, cuatro y cinco satélites eran extraños, configuraciones orbitales muy asimétricas, con los satélites colocados alternando huecos grandes y pequeños, en lugar de huecos de igual tamaño como habrían hecho las técnicas convencionales. Sin embargo, esta solución redujo significativamente los tiempos medio y máximo de apagón, en algunos casos hasta en 90 minutos. En un artículo periodístico, el Dr. William Crossley señaló que ``ingenieros con años de experiencia aeroespacial quedaorn sorprendidos con el rendimiento ofrecido por el diseño no convencional''.
Keane y Brown 1996[43] utilizadon un AG para producir un nuevo diseño para un brazo o jirafa para transportar carga que pudiese montarse en órbita y utilizarse con satélites, estaciones espaciales y otros proyectos de construcción aeroespacial. El resultado, una estructura retorcida con aspecto orgánico que se ha comparado con un fémur humano, no utiliza más material que el diseño de brazo estándar, pero es ligera, fuerte y muy superior a la hora de amortiguar las vibraciones perjudiciales, como confirmaron las pruebas reales del producto final. Y sin embargo ``Ninguna inteligencia produjo los diseños. Simplemente evolucionaron'' (Petit 1998[43]). Los autores del artículo comentan además que su AG sólo se ejecutó durante 10 generaciones, debido a la naturaleza computacionalmente costosa de la simulación, y la población no se había estancado todavía. Haber proseguido la ejecución durante más generaciones habría producido indudablemente mayores mejoras de rendimiento.
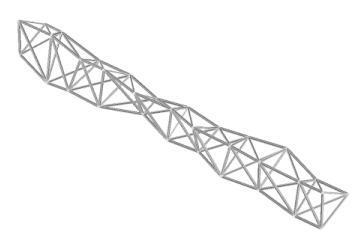
|
Finalmente, como informa Gibbs 1996[25], Lockheed Martin ha utilizado un algoritmo genético para producir mediante evolución una serie de maniobras para mover una nave espacial de una orientación a otra, dentro del 2% del tiempo mínimo teórico para tales maniobras. La solución evolucionada era un 10% más rápida que una solución producida manualmente por un experto para el mismo problema.
Charbonneau 1995[12] sugiere la utilidad de los AGs para problemas de astrofísica, aplicándolos a tres problemas de ejemplo: obtener la curva de rotación de una galaxia basándose en las velocidades rotacionales observadas de sus componentes, determinar el periodo de pulsación de una estrella variable basándose en series de datos temporales, y sacar los valores de los parámetros críticos de un modelo magnetohidrodinámico del viento solar. Son tres difíciles problemas no lineales y multidimensionales.
El algoritmo genético de Charbonneau, PIKAIA, utiliza selección generacional y proporcional a la aptitud, junto con elitismo, para asegurar que el mejor individuo se copia una vez hacia la siguiente generación sin ninguna modificación. PIKAIA tiene un ritmo de cruzamiento de 0,65 y un ritmo de mutación variable que se pone a 0,003 inicialmente y luego aumenta gradualmente, mientras la población se aproxima a la convergencia, para mantener la variabilidad en el acervo genético.
En el problema de la curva de rotación galáctica, el AG produjo dos curvas, y ambas estaban bien ajustadas a los datos (un resultado común en este tipo de problema, en el que hay poco contraste entre cimas cercanas); observaciones posteriores pueden distinguir cuál es la preferible. En el problema de la serie temporal, el AG fue impresionantemente exitoso, generando un ajuste de los datos de gran calidad, aunque otros problemas más difíciles no se ajustaron tan bien (aunque, como señala Charbonneau, estos problemas son igualmente difíciles de resolver con técnicas convencionales). El artículo sugiere que un AG híbrido que emplee tanto evolución artificial como técnicas analíticas estándar, podría funcionar mejor. Finalmente, en el problema de obtener los seis parámetros críticos del viento solar, el AG determinó con éxito el valor de tres con una precisión de menos del 0,1% y los otros tres con precisiones entre el 1 y el 10%. (Aunque siempre serían preferibles unos errores experimentales menores para estos tres parámetros, Charbonneau señala que no existe ningún otro método eficiente y robusto para resolver experimentalmente un problema no lineal 6-dimensional de este tipo; un método de gradiente conjugado funciona ``siempre que se pueda proporcionar un valor inicial muy acertado'' (p. 323). En contraste, los AGs no requieren un conocimiento del dominio tan bien afinado).
Basándose en los resultados obtenidos hasta ahora, Charbonneau sugiere que los AGs pueden y deben encontrar uso en otros problemas difíciles de astrofísica, en particular, problemas inversos como las imágenes por Doppler y las inversiones heliosísmicas. Para terminar, Charbonneau sostiene que los AGs son un ``contendiente poderoso y prometedor'' (p. 324) en este campo, del que se puede esperar que complemente (no sustituya) a las técnicas tradicionales de optimización, y concluye que ``el punto decisivo, si es que tiene que haber alguno, es que los algoritmos genéticos funcionan, y a menudo colosalmente bien'' (p. 325).
Un pulso láser ultracorto de alta energía puede romper moléculas complejas en moléculas más sencillas, un proceso con aplicaciones importantes en la química orgánica y la microelectrónica. Los productos específicos de una reacción así pueden controlarse modulando la fase del pulso láser. Sin embargo, para moléculas grandes, obtener la forma del pulso deseado de manera analítica es demasiado difícil: los cálculos son demasiado complejos y las características relevantes (las superficies de energía potencial de las moléculas) no se conocen con suficiente precisión.
Assion et al. 1998[6] resolvieron este problema utilizando un algoritmo evolutivo para diseñar la forma del pulso. En lugar de introducir información compleja, específica del problema, sobre las características cuánticas de las moléculas iniciales, para diseñar el pulso conforme a las especificaciones, el AE dispara un pulso, mide las proporciones de las moléculas producto resultantes, muta aleatoriamente las características del rayo con la esperanza de conseguir que estas proporciones se acerquen a la salida deseada, y el proceso se repite. (En lugar de afinar directamente las características del rayo láser, el AG de los autores representa a los individuos como un conjunto de 128 números, en el que cada número es un valor de voltaje que controla el índice de refracción de uno de los pixeles del modulador láser. De nuevo, no se necesita un conocimiento específico del problema sobre las propiedades del láser o de los productos de la reacción). Los autores afirman que su algoritmo, cuando se aplica a dos sustancias de muestra, ``encuentra automáticamente la mejor configuración... no importa lo complicada que sea la respuesta molecular'' (p. 921), demostrando un ``control coherente automatizado de los productos que son químicamente diferentes uno del otro y de la molécula padre'' (p. 921).
A principios y mediados de los 90, la amplia adopción de una novedosa técnica de diseño de fármacos, llamada química combinatoria, revolucionó la industria farmacéutica. Con este método, en lugar de la síntesis precisa y meticulosa de un sólo compuesto de una vez, los bioquímicos mezclan deliberadamente una gran variedad de reactivos para producir una variedad aún mayor de productos -cientos, miles o millones de compuestos diferentes en cada remesa- que luego pueden aislarse rápidamente para su actividad bioquímica. Hay dos formas de diseñar las bibliotecas de reactivos en esta técnica: diseño basado en los reactivos, que elige grupos optimizados de reactivos sin considerar qué productos saldrán como resultado, y diseño basado en los productos, que selecciona los reactivos que producirán con mayor probabilidad los productos con las propiedades deseadas. El diseño basado en los productos es más difícil y complejo, pero se ha demostrado que genera bibliotecas combinatorias mejores y más diversas, y tiene más probabilidades de ofrecer un resultado útil.
En un artículo patrocinado por el departamento de investigación y desarrollo de GlaxoSmithKline, Gillet 2002[26] describe el uso de un algoritmo genético multiobjetivo para el diseño basado en los productos de bibliotecas combinatorias. Al elegir los componentes que van en una biblioteca particular, deben considerarse características como la diversidad y peso molecular, el coste de los suministros, la toxicidad, la absorción, la distribución y el metabolismo. Si el objetivo es encontrar moléculas similares a una molécula existente con una función conocida (un método común en el diseño de nuevos fármacos), también se puede tener en cuenta la similaridad estructural. Este artículo presenta un enfoque multiobjetivo, donde puede desarrollarse un conjunto de resultados paretianos que maximicen o minimicen cada uno de estos objetivos. El autor concluye diciendo que el AG fue capaz de satisfacer simultáneamente los criterios de diversidad molecular y eficiencia sintética máxima, y también fue capaz de encontrar moléculas parecidas a un fármaco que eran ``muy similares a las moléculas objetivo dadas, tras explorar una fracción muy pequeña del espacio de búsqueda total'' (p. 378).
En un artículo relacionado, Glen y Payne 1995[28] describen el uso de algoritmos genéticos para diseñar automáticamente moléculas nuevas desde cero que se ajustan a un conjunto de especificaciones dado. Dada una población inicial, bien generada aleatoriamente o utilizando la sencilla molécula del etano como semilla, el AG añade, elimina y altera aleatoriamente átomos y fragmentos moleculares con el objetivo de generar moléculas que se ajusten a los requisitos dados. El AG puede optimizar simultáneamente un gran número de objetivos, incluyendo el peso molecular, el volumen molecular, el número de enlaces, el número de centros quirales, el número de átomos, el número de enlaces rotables, la polarizabilidad, el momento dipolar, etcétera, para producer moléculas candidatas con las propiedades deseadas. Basándose en pruebas experimentales, incluyendo un difícil problema de optimización que implicaba la generación de moléculas con propiedades similares a la ribosa (un componente del azúcar imitado a menudo en los fármacos antivirales), los autores concluyen que el AG es un ``excelente generador de ideas'' (p. 199) que ofrece ``propiedades de optimización rápidas y poderosas'' y puede generar ``un conjunto diverso de estructuras posibles'' (p. 182). Continúan afirmando: ``Es de interés especial la poderosa capacidad de optimización del algoritmo genético, incluso con tamaños de población relativamente pequeños'' (p. 200). Como prueba de que estos resultados no son simplemente teóricos, Lemley 2001[45] informa de que la empresa Unilever ha utilizado algoritmos genéticos para diseñar nuevos componentes antimicrobianos para su uso en productos de limpieza, algo que ha patentado.
Una matriz de puertas programable en campo (Field Programmable Gate Array, o FPGA), es un tipo especial de placa de circuito con una matriz de celdas lógicas, cada una de las cuales puede actuar como cualquier tipo de puerta lógica, interconectado con conexiones flexibles que pueden conectar celdas. Estas dos funciones se controlan por software, así que simplemente cargando un programa especial en la placa, puede alterarse al vuelo para realizar las funciones de cualquier dispositivo de hardware de la amplia variedad existente.
El Dr. Adrian Thompson ha explotado este dispositivo, en conjunción con los principios de la evolución, para producir un prototipo de circuito reconocedor de voz que puede distinguir y responder a órdenes habladas utilizando sólo 37 puertas lógicas -una tarea que se habría considerado imposible para cualquier ingeniero humano. Generó cadenas aleatorias de bits de ceros y unos y las utilizó como configuraciones de la FPGA, seleccionando los individuos más aptos de cada generación, reproduciéndolos y mutándolos aleatoriamente, intercambiando secciones de su código y pasándolo hacia la siguiente ronda de selección. Su objetivo era evolucionar un dispositivo que pudiera en principio discriminar entre tonos de frecuencias distintas (1 y 10 kilohercios), y luego distinguir entre las palabras habladas ``go'' (adelante) y ``stop'' (para).
Su objetivo se alcanzó en 3.000 generaciones, pero el éxito fue mayor de lo que había anticipado. El sistema que evolucionó utilizaba muchas menos celdas que cualquier cosa que pudiera haber diseñado un ingeniero humano, y ni siquiera necesita del componente más crítico de los sistemas diseñados por humanos -un reloj. ¿Cómo funcionaba? Thompson no tiene ni idea, aunque ha rastreado la señal de entrada a través de un complejo sistema de bucles realimentados del circuito evolucionado. De hecho, de las 37 puertas lógicas que utiliza el producto final, cinco de ellas ni siquiera están conectadas al resto del circuito de ninguna manera -pero si se les retira la alimentación eléctrica, el circuito deja de funcionar. Parece que la evolución ha explotado algún sutil efecto electromagnético de estas celdas para alcanzar su solución, pero el funcionamiento exacto de la compleja e intrincada estructura evolucionada sigue siendo un misterio (Davidson 1997[19]).
Altshuler y Linden 1997[2] utilizaron un algoritmo genético para evolucionar antenas de alambre con propiedades especificadas a priori. Los autores señalan que el diseño de tales antenas es un proceso impreciso, comenzando con las propiedades deseadas y luego determinando la forma de la antena mediante ``conjeturas... intuición, experiencia, ecuaciones aproximadas o estudios empíricos'' (p. 50). Esta técnica requiere mucho tiempo, a menudo no produce resultados óptimos y tiende a funcionar bien sólo con diseños simétricos y relativamente simples. En contraste, con el método del algoritmo genético, el ingeniero especifica las propiedades electromagnéticas de la antena, y el AG sintetiza automáticamente una configuración que sirva.
Altshuler y Linden utilizaron su AG para diseñar una antena de siete segmentos polarizada circularmente con una cobertura hemisférica; el resultado se muestra a la izquierda. Cada individuo del AG consistía en un cromosoma binario que especificaba las coordenadas tridimensionales de cada extremo final de cada alambre. La aptitud se evaluaba simulando a cada candidato de acuerdo con un código de cableado electromagnético, y el individuo mejor de cada ronda se construía y probaba. Los autores describen la forma de esta antena, que no se parece a las antenas tradicionales y carece de una simetría obvia, como ``inusualmente extraña'' y ``antiintuitiva'' (p. 52), aunque tenía un patrón de radiación casi uniforme y con un gran ancho de banda tanto en la simulación como en la prueba experimental, adecuándose excelentemente a la especificación inicial. Los autores concluyen que un método basado en algoritmos genéticos para diseñar antenas se muestra ``excepcionalmente prometedor''. ``... este nuevo procedimiento de diseño es capaz de encontrar antenas genéticas capaces de resolver de manera efectiva difíciles problemas de antenas, y será especialmente útil en situaciones en las que los diseños existentes no sean adecuados'' (p. 52).
Mahfoud y Mani 1996[46] utilizaron un algoritmo genético para predecir el rendimiento futuro de 1.600 acciones ofertadas públicamente. Concretamente, al AG se le asignó la tarea de predecir el beneficio relativo de cada acción, definido como el beneficio de esa acción menos el beneficio medio de las 1.600 acciones a lo largo del periodo de tiempo en cuestión, 12 semanas (un cuarto del calendario) en el futuro. Como entrada, al AG se le proporcionaron datos históricos de cada acción en forma de una lista de 15 atributos, como la relación precio-beneficio y el ritmo de crecimiento, medidos en varios puntos del tiempo pasado; se le pidió al AG que evolucionara un conjunto de reglas si/entonces para clasificar cada acción y proporcionar, como salida, una recomendación sobre qué hacer con respecto a la acción (comprar, vender o ninguna predicción) y un pronóstico numérico del beneficio relativo. Los resultados del AG fueron comparados con los de un sistema establecido, basado en una red neuronal, que los autores habían estado utilizando para pronosticar los precios de las acciones y administrar las carteras de valores durante tres años. Por supuesto, el mercado de valores es un sistema extremadamente ruidoso y no lineal, y ningún mecanismo predictivo puede ser correcto el 100% del tiempo; el reto consiste en encontrar un predictor que sea preciso más de la mitad de las veces.
En el experiemnto, el AG y la red neuronal hicieron pronósticos al final de la semana para cada una de las 1.600 acciones, durante doce semanas consecutivas. Doce semanas después de cada predicción, se comparó el rendimiento verdadero con el beneficio relativo predicho. Globalmente, el AG superó significativamente a la red neuronal: en una ejecución de prueba, el AG predijo correctamente la dirección de una acción el 47,6% de las veces, no hizo predicción el 45,8% de las veces y realizó una predicción incorrecta sólo un 6.6% de las veces, una precisión predictiva total de un 87,8%. Aunque la red neuronal realizó predicciones precisas más a menudo, también hizo predicciones erróneas más a menudo (de hecho, los autores especulan que la mayor capacidad del AG para no realizar predicciones cuando los datos eran dudosos fue un factor de su éxito; la red neuronal siempre produce una predicción a menos que sea restringida explícitamente por el programador). En el experimento de las 1.600 acciones, el AG produjo un beneficio relativo de un +5,47%, contra el +4,40% de la red neuronal -una diferencia estadísticamente significativa. De hecho, el AG también superó significativamente a tres índices bursátiles importantes -el S&P 500, el S&P 400 y el Russell 2000- en este periodo; la casualidad fue excluída como causa de este resultado con un margen de confianza de un 95%. Los autores atribuyen este convincente éxito a la capacidad del algoritmo genético de percatarse de relaciones no lineales difícilmente evidentes para los observadores humanos, además del hecho de que carece del ``prejuicio contra las reglas antiintuitivas y contradictorias'' (p. 562) de los expertos humanos.
Andreou, Georgopoulos y Likothanassis 2002[4] lograron un éxito similar utilizando algoritmos genéticos híbridos para evolucionar redes neuronales que predijeran los tipos de cambio de monedas extranjeras hasta un mes en el futuro. Al contrario que en el ejemplo anterior, donde competían AGs y redes neuronales, aquí los dos trabajaron conjuntamente: el AG evolucionó la arquitectura (número de unidades de entrada, número de unidades ocultas y la estructura de enlaces entre ellas) de la red, que luego era entrenada por un algoritmo de filtro.
Se le proporciaron al algoritmo 1.300 valores brutos diarios de cinco divisas como información histórica -el dólar estadounidense, el marco alemán, el franco francés, la libra esterlina y el dracma griego- y se le pidió que predijera sus valores futuros para los 1, 2, 5 y 20 días posteriores. El rendimiento del AG híbrido mostró, en general, un ``nivel excepcional de precisión'' (p. 200) en todos los casos probados, superando a otros varios métodos, incluyendo a las redes neuronales en solitario. Los autores concluyen que ``se ha logrado un excepcional éxito predictivo tanto con un horizonte predictivo de un paso como de varios pasos'' (p. 208) -de hecho, afirman que sus resultados son mejores con diferencia que cualquier estrategia predictiva relacionada que se haya aplicado en esta serie de datos u otras divisas.
La utilización de los AGs en los mercados financieros ha empezado a extenderse en las empresas de corretaje bursátil del mundo real. Naik 1996[48] informa de que LBS Capital Management, una empresa estadounidense cons ede en Florida, utiliza algoritmos genéticos para escoger las acciones de los fondos de pensiones que administra. Coale 1997[17] y Begley y Beals 1995[9] informan de que First Quadrant, una empresa de inversiones de Californa que mueve más de 2.200 millones de dólares, utiliza AGs para tomar decisiones de inversión en todos sus servicios financieros. Su modelo evolucionado gana, de media, 225 dólares por cada 100 dólares invertidos durante seis años, en contraste con los 205 dólares de otros tipos de sistemas de modelos.
Una de las demostraciones más novedosas y persuasivas de la potencia de los algoritmos genéticos la presentaron Chellapilla y Fogel 2001[13], que utilizaron un AG para evolucionar redes neuronales que pudieran jugar a las damas. Los autores afirman que una de las mayores dificultades en este tipo de problemas relacionados con estrategias es el problema de la asignación de crédito -en otras palabras, ¿cómo escribir una función de aptitud? Se ha creído ampliamente que los criterios simples de ganar, perder o empatar no proporcionan la suficiente información para que un algoritmo genético averigüe qué constituye el buen juego.
En este artículo, Chellapila y Fogel echan por tierra esa suposición. Dados sólo las posiciones espaciales de las piezas en el tablero y el número total de piezas que posee cada jugador, fueron capaces de evolucionar un programa de damas que jugaba a un nivel competitivo con expertos humanos, sin ninguna información de entrada inteligente acerca de lo que constituye el buen juego -es más, ni siquiera se les dijo a los individuos del algoritmo evolutivo cuál era el criterio para ganar, ni se les dijo el resultado de ningún juego.
En la representación de Chellapilla y Fogel, el estado del juego estaba representado por una lista numérica de 32 elementos, en donde cada posición de la lista correspondía a una posición disponible en el tablero. El valor de cada posición era 0 para una casilla desocupada, -1 si esa casilla estaba ocupada por una pieza enemiga, +1 si la casilla estaba ocupada por una de las piezas del programa, y -K o +K si la casilla estaba ocupada por una dama enemiga o amiga. (El valor de K no se especificaba a priori, sino que, de nuevo, era determinado por la evolución durante el curso del algoritmo). Acompañando a todo esto había una red neuronal con múltiples capas de procesamiento y una capa de entrada con un nodo para cada una de las 4x4, 5x5, 6x6, 7x7 y 8x8 posibles casillas del tablero. La salida de la red neuronal para una colocación de las piezas dada era un valor entre -1 y +1, que indicaba cómo de buena le parecía esa posición. Para cada movimiento, se le presentaba a la red neuronal un árbol de juego que contenía todos los movimientos posibles hasta cuatro turnos en el futuro, y el movimiento se decidía basándose en qué rama del árbol producía los mejores resultados.
El algoritmo evolutivo comenzó con una población de 15 redes neuronales con pesos y tendencias, generados aleatoriamente, asignados a cada nodo y conexión; luego, cada individuo se reprodujo una vez, generando una descendencia con variaciones en los valores de la red. Luego estos 30 individuos compitieron por la supervivencia jugando entre ellos; cada individuo compitió en cada turno con 5 oponentes elegidos aleatoriamente. Se otorgó 1 punto a cada victoria y se descontaban 2 puntos por cada derrota. Se seleccionaron los 15 mejores jugadores en relación a su puntuación total, y el proceso se repitió. La evolución continuó durante 840 generaciones más (aproximadamente seis meses de tiempo de computación).
| Clase | Puntuación |
| Gran Maestro | +2.400 |
| Maestro | 2.200-2.399 |
| Experto | 2.000-2.199 |
| Clase A | 1.800-1.999 |
| Clase B | 1.600-1.799 |
| Clase C | 1.400-1.599 |
| Clase J | <200 |
El mejor individuo que surgió de esta selección fue inscrito como competidor en la página web de juegos http://www.zone.com. Durante un periodo de dos meses, jugó contra 165 oponentes humanos que componían una gama de niveles altos, desde clase C a maestros, de acuerdo con el sistema de clasificaciones de la Federación de Ajedrez de Estados Unidos (mostrado a la izquierda, con algunos rangos omitidos en aras de claridad). De estas partidas, la red neuronal ganó 94, perdió 39 y empató 32; en base a las clasificaciones de los oponentes en estas partidas, la red neuronal evolucionada era equivalente a un jugador con una puntuación media de 2.045,85, colocándola en el nivel experto -una clasificación superior a la del 99,61% de los 80.000 jugadores registrados en la página web. Una de las victorias más significativas de la red neuronal fue cuando venció a un jugador clasificado en la posición 98 de todos los jugadores registrados, cuya puntuación estaba tan sólo 27 puntos por debajo del nivel de maestro.
Las pruebas realizadas con un sencillo programa diferencial en las piezas (que basa sus movimientos solamente en la diferencia entre el número de piezas que quedan en cada lado) con una capacidad de anticipación de 8 movimientos demostró que la red neuronal era significativamente superior, con una puntuación de más de 400 puntos por encima. ``Un programa que se basa sólo en el número de piezas y en una búsqueda de ocho capas vencerá a muchas personas, pero no es un experto. La mejor red neuronal evolucionada sí lo es'' (p. 425). Aunque podía buscar posiciones dos movimientos más lejos que la red neuronal, el programa diferencial en las piezas perdió contundentemente 8 de 10 partidas. Esto demuestra concluyentemente que la red neuronal evolucionada no sólo está contando piezas, sino que de alguna manera procesa las características espaciales del tablero para decidir sus movimientos. Los autores señalan que los oponentes de zone.com que los movimientos de la red neuronal eran ``extraños'', pero su nivel global de juego fue descrito como ``muy duro'' o con términos elogiosos similares.
Para probar más a la red neuronal evolucionada (a la que los autores nombraron ``Anaconda'' porque a menudo ganaba restringiendo la movilidad de sus oponentes), jugó contra un programa de damas comercial, el Hoyle Classic Games, distribuído por Sierra Online (Chellapilla y Fogel 2000[14]). Este programa viene con un surtido de personajes incorporados, cada uno con un nivel de juego distinto. Anaconda se puso a prueba con tres personajes (``Beatrice'', ``Natasha'' y ``Leopold'') designados como jugadores expertos, jugando una partida con las rojas y otra partida con las blancas contra cada uno de ellos con una capacidad de anticipación de 6 movimientos. Aunque los autores dudaban de que esta profundidad de anticipación pudiera darla a Anaconda la capacidad de juego experto que demostró anteriormente, consiguió seis victorias seguidas de las seis partidas jugadas. Basándose en este resultado, los autores expresaron escepticismo sobre si el software Hoyle jugaba al nivel que anunciaba, ¡aunque debe señalarse que llegaron a esta conclusión basándose solamente en la facilidad con la que Anaconda le venció!
La prueba definitiva de Anaconda se detalla en Chellapilla y Fogel 2002[15], cuando la red neuronal evolucionada jugó contra el mejor jugador de damas del mundo: Chinook, un programa diseñado principalmente por el Dr. Jonathan Schaeffer, de la Universidad de Alberta. Con una puntuación de 2.814 en 1996 (mientras que sus competidores humanos más cercanos andan por los 2.600), Chinook incorpora un libro de movimientos de apertura proporcionado por grandes maestros humanos, un conjunto sofisticado de algoritmos de juego para la parte central de la partida, y una base de datos completa de todos los movimientos posibles cuando quedan en el tablero 10 piezas o menos, de manera que nunca comete un error durante un final de partida. Se invirtió una cantidad enorme de inteligencia y experiencia humana en el diseño de este programa.
Chellapilla y Fogel enfrentaron a Anaconda y Chinook en un torneo de 10 partidas, con Chinook jugando al nivel de 5 capas de anticipación, aproximándolo más o menos al nivel de maestro. Chinook ganó esta competición, cuatro victorias a dos, con cuatro empates. (Curiosamente, como señalan los autores, en dos de las partidas que acabaron con empate, Anaconda lideraba con cuatro damas mientras que Chinook tenía tres. Además, una de las victorias de Chinook vino tras una serie de movimientos con búsqueda de 10 capas sacados de su base de datos de finales de partida; unos movimientos que Anaconda, con una anticipación de 8 capas, no pudo anticipar. Si Anaconda hubiera tenido acceso a una base de datos de finales de partida de la misma calidad de la de Chinook, el resultado del torneo bien podría haber sido el de victoria para Anaconda, cuatro a tres). Estos resultados ``proporcionan un buen sustento a la puntuación de experto que se ganó Anaconda en www.zone.com'' (p. 76), con una puntuación global de 2.030-2.055, comparable a la puntuación de 2.045 que ganó jugando contra humanos. Aunque Anaconda no es un jugador invulnerable, es capaz de jugar competitivamente en el nivel experto y comportarse ante una variedad de jugadores de damas humanos extremadamente hábiles. Cuando uno considera los criterios de aptitud tan sencillos con los que se obtuvieron estos resultados, el surgimiento de Anaconda proporciona una espectacular corroboración del poder de la evolución.
Sambridge y Gallaguer 1993[56] utilizaron un algoritmo genético para los hipocentros de los terremotos basándose en datos sismológicos. (El hipocentro es el punto bajo la superficie terrestre en el que se origina un terremoto. El epicentro es el punto de la superficie directamente encima del hipocentro). Esto es una tarea sumamente compleja, ya que las propiedades de las ondas sísmicas dependen de las propiedades de las capas de roca a través de las que viajan. El método tradicional para localizar el hipocentro se basa en lo que se conoce como algoritmo de inversión sísmico, que empieza con la mejor estimación de la ubicación, calcula las derivadas del tiempo de viaje de la onda con respecto al punto de origen, y realiza una operación de matriz para proporcionar una ubicación actualizada. Este proceso se repite hasta que se alcanza una solución aceptable. (Este Mensaje del Mes, de noviembre de 2003, proporciona más información). Sin embargo, este método requiere información diferencial y es propenso a quedar atrapado en óptimos locales.
Un algoritmo de localización que no dependa de información diferencial o modelos de velocidad puede evitar esta deficiencia calculando sólo el problema directo -la diferencia entre los tiempos de llegada de la onda observados y predichos para distintas localizaciones del hipocentro. Sin embargo, un método de búsqueda exhaustivo basado en este método sería demasiado costoso computacionalmente. Éste, por supuesto, es precisamente el tipo de problema de optimización en el que destacan los algoritmos genéticos. Como todos los AGs, el propuesto por el artículo citado es paralelo en naturaleza -en lugar de mover un solo hipocentro más y más cerca hacia la solución, comienza con una nube de hipocentros potenciales que encoge con el tiempo hasta converger en una sola solución. Los autores afirman que su método ``puede localizar rápidamente soluciones casi óptimas sin una búsqueda exhaustiva del espacio de parámetros'' (p. 1.467), muestra ``un comportamiento muy organizado que produce una búsqueda eficiente'' y es ``un compromiso entre la eficiencia de los métodos basados en derivadas y la robustez de una búsqueda exhaustiva completamente no lineal'' (p. 1.469). Los autores concluyen que su algoritmo genético es ``eficiente para una verdadera optimización global'' (p. 1.488) y ``una herramienta nueva y poderosa para realizar búsquedas robustas de hipocentros'' (p. 1.489).
Giro, Cyrillo y Galvão 2002[27] utilizaron algoritmos genéticos para diseñar polímeros conductores de electricidad basados en el carbono, conocicos como polianilinas. Estos polímeros, un tipo de material sintético inventado recientemente, tienen ``grandes aplicaciones tecnológicas potenciales'' y podrían abrir la puerta a ``nuevos fenómenos físicos fundamentales'' (p. 170). Sin embargo, debido a su alta reactividad, los átomos de carbono pueden formar un número virtualmente infinito de estructuras, haciendo que la búsqueda de nuevas moléculas con propiedades interesantes sea del todo imposible. En este artículo, los autores aplican un enfoque basado en AGs a la tarea de diseñar moléculas nuevas con propiedades especificadas a priori, comenzando con una población de candidatos iniciales generada aleatoriamente. Concluyen que su metodología puede ser una ``herramienta muy efectiva'' (p. 174) para guiar a los investigadores en la búsqueda de nuevos compuestos y es lo suficientemente general para que pueda extenderse al diseño de nuevos materiales que pertenezcan virtualmente a cualquier tipo de molécula.
Weismann, Hammel, y Bäck 1998[63] aplicaron algoritmos evolutivos a un problema industrial ``no trivial'' (p. 162): el diseño de revestimientos ópticos multicapa para filtros que reflejan, transmiten o absorben luz de frecuencias especificadas. Estos revestimientos se utilizan en la fabricación de gafas de sol, por ejemplo, o discos compactos. Su fabricación es una tarea precisa: las capas deben colocarse en una secuencia particular y con un grosor particular para producir el resultado deseado, y las variaciones incontrolables del entorno de fabricación, como la temperatura, la polución o la humedad, pueden afectar al rendimiento del producto acabado. Muchos óptimos locales no son robustos ante estas variaciones, lo que significa que una mayor calidad del producto se paga con una tasa mayor de desviaciones indeseadas. El problema particular considerado en este artículo también tenía múltiples criterios: además de la reflectancia, también se consideró la composición espectral (color) de la luz reflejada.
El AE actuó variando el número de capas de revestimiento y el grosor de cada una de ellas, y produjo diseños que eran ``sustancialmente más robustos a la variación de parámetros'' (p. 166) y tenían un rendimiento medio mayor que los métodos tradicionales. Los autores concluyen que ``los algoritmos evolutivos pueden competir e incluso superar a los métodos tradicionales'' (p. 167) de diseño de revestimientos ópticos multicapa, sin tener que incorporar un conocimiento específico del dominio en la función de búsqueda y sin tener que alimentar a la población con buenos diseños iniciales.
Es digno de mención otro uso de los AGs en el campo de la ingeniería de materiales: Robin et al. 2003[54] utilizaron AGs para diseñar patrones de exposición para un haz de electrones de litografía, utilizado para grabar estructuras a una escala menor a la del micrómetro en circuitos integrados. Diseñar estos patrones es una tarea muy difícil; es pesado y costoso determinarlos experimentalmente, pero la alta dimensionalidad del espacio de búsqueda frustra a la mayoría de los algoritmos de búsqueda. Deben optimizarse simultáneamente hasta 100 parámetros para controlar el haz de electrones y evitar la dispersión y efectos de proximidad que arruinarían las estructuras finas que se estén esculpiendo. El problema directo -determinar la estructura resultante como función de la cantidad de electrones- es sencillo y fácil de simular, pero el problema inverso de determinar la cantidad de electrones para producir una estructura dada, que es lo que se pretende resolver aquí, es mucho más difícil y no existe una solución determinista.
Se aplicaron algoritmos genéticos a este problema, ya que ``se sabe que son capaces de encontrar soluciones buenas a problemas muy complejos de alta dimensionalidad'' (p. 75) sin necesidad de proporcionarles información específica del dominio acerca de la topología del paisaje de búsqueda. Los autores del artículo emplearon un AG de estado estacionario con selección por rueda de ruleta en una simulación por computador, que produjo unos patrones de exposición ``muy bien optimizados'' (p. 77). En contraste, se utilizó un tipo de trepacolinas conocido como algoritmo bajacolinas-simplex (simplex-downhill) en el mismo problema, sin éxito; el método BS quedaba rápidamente atrapado en óptimos locales de los que no podía escapar, produciendo soluciones de poca calidad. Un híbrido entre los métodos del AG y el BS tampoco pudo mejorar los resultados ofrecidos por el AG en solitario.
Aunque algunas de las aplicaciones más prometedoras y las demostraciones más convincentes de la potencia de los AGs se encuentran en el campo de la ingeniería de diseño, también son relevantes en problemas ``puramente'' matemáticos. Haupt y Haupt 1998[34] (p. 140) describen el uso de AGs para resolver ecuaciones de derivadas parciales no lineales de alto orden, normalmente encontrando los valores para los que las ecuaciones se hacen cero, y dan como ejemplo una solución casi perfecta para los coeficientes de la ecuación de quinto orden conocida como Super Korteweg-de Vries.
Ordenar una lista de elementos es una tarea importante en la informática, y una red de ordenación es una manera eficiente de conseguirlo. Una red de ordenación es una lista fija de comparaciones realizadas en un conjunto de un tamaño dado; en cada comparación se comparan dos elementos y se intercambian si no están en orden. Koza et al. 1999[41] (p. 952) utilizaron programación genética para evolucionar redes de ordenación mínimas para conjuntos de 7 elementos (16 comparaciones), conjuntos de 8 elementos (19 comparaciones) y conjuntos de 9 elementos (25 comparaciones). Mitchell 1996[47], p. 21, describe el uso de algoritmos genéticos por W. Daniel Hillis para encontrar una red de ordenación de 61 comparaciones para un conjunto de 16 elementos, sólo un paso más allá de la más pequeña conocida. Este último ejemplo es especialmente interesante por las dos innovaciones que utiliza: cromosomas diploides y, más notablemente, coevolución de huésped/parásito. Tanto las redes de búsqueda como los casos de prueba evolucionaron conjuntamente; se les otorgó mayor aptitud a las redes de ordenación que ordenaran correctamente un mayor número de casos de prueba, mientras que se les otorgó mayor aptitud a los casos de prueba que pudieran ``engañar'' a un mayor número de redes de búsqueda para que ordenaran incorrectamente. El AG con coevolución rindió significativamente mejor que el mismo AG sin ella.
Un ejemplo final de AG digno de mención en el campo de la algoritmia puede encontrarse en Koza et al. 1999[41], que utilizó programación genética para descubrir una regla para el problema de clasificación por mayoría en autómatas celulares de una dimensión, una regla mejor que todas las reglas conocidas escritas por humanos. Un autómata celular de una dimensión puede imaginarse como una cinta finita con un número dado de posiciones (celdas) en ella, cada una de las cuales puede contener el estado 0 o el estado 1. El autómata se ejecuta durante un número dado de pasos temporales; en cada paso, cada celda adquiere un nuevo valor basado en su valor anterior y el valor de sus vecinos más cercanos. (El Juego de la Vida es un autómata celular bidimensional). El problema de la clasificación por mayoría implica encontrar una tabla de reglas tal que si más de la mitad de las celdas de la cinta son 1 inicialmente, todas las celdas se ponen a 1; de lo contrario, todas las celdas se ponen a 0. El reto consiste en el hecho de que cualquier celda individual sólo tiene acceso a información acerca de sus vecinos más cercanos; por lo tanto, los conjuntos de reglas buenos deben encontrar de algún modo una manera de transmitir información sobre regiones distantes de la cinta.
Se sabe que no existe una solución perfecta a este problema -ningún conjunto de reglas puede clasificar con precisión todas las configuraciones iniciales posibles-, pero durante los últimos veinte años ha habido una larga sucesión de soluciones cada vez mejores. En 1978, tres investigadores desarrollaron la famosa regla GKL, que clasifica correctamente un 81,6% de los posibles estados iniciales. En 1993, se descubrió una regla mejor con una precisión de un 81,8%; en 1995 se encontró otra regla con una precisión de un 82,178%. Todas estas reglas requirieron para su desarrollo de un esfuerzo significativo por parte de humanos inteligentes y creativos. En contraste, la mejor regla descubierta mediante programación genética, descrito en Koza et al. 1999[41], p. 973, tiene una precisión total de 82,326% -mejor que cualquiera de las soluciones humanas desarrolladas durante las dos últimas décadas. Los autores señalan que sus nuevas reglas son cualitativamente distintas a las reglas publicadas con anterioridad, al emplear representaciones internas muy detalladas de la densidad de estados y conjuntos intrincados de señales para comunicar información a largas distancias.
Kewley y Embrechts 2002[39] utilizaron algoritmos genéticos para evolucionar planes tácticos para las batallas militares. Los autores señalan que ``planear una batalla militar táctica es una tarea compleja multidimensoinal que a menudo atormenta a los profesionales experimentados'' (p. 163), no sólo porque este tipo de decisiones a menudo se toman bajo condiciones de mucho estrés, sino también porque hasta los planes más sencillos requieren tomar en cuenta un gran número de variables y consecuencias: minimizar las bajas amigas, maximizar las bajas enemigas, controlar el terreno deseado, conservar recursos, etcétera. Los planificadores humanos tienen dificultades al tratar con las complejidades de esta tarea y a menudo deben recurrir a métodos ``rápidos y sucios'', como hacer lo que funcionase la última vez.
Para superar estas dificultades, los autores del artículo citado desarrollaron un algoritmo genético para automatizar la creación de planes de batalla, en conjunción con un programa gráfico de simulación de batallas. El comandante introduce el resultado deseado y el AG evoluciona automáticamente un plan de batalla; en la simulación utilizada, se tomaron en cuenta factores como la topografía del terreno, la cobertura vegetal, la velocidad del movimiento de tropas, y la precisión en los disparos. En este experimento también se utilizó la coevolución para mejorar la calidad de las soliciones: los planes de batalla de las fuerzas enemigas evolucionaron simultáneamente con los planes amigos, forzando al AG a corregir cualquier debilidad de su plan que pudiese explotar el enemigo. Para medir la calidad de las soluciones producidas por el AG, se compararon con planes de batalla para el mismo escenario producidos por un grupo de ``expertos militares experimentados... considerados muy capaces de desarrollar planes de acción para el tamaño de las fuerzas utilizadas en este experimento'' (p. 166). Estos avezados expertos desarrollaron su propio plan y, cuando la solución del AG estuvo acabada, se les dio la oportunidad de examinarla y modificarla como vieran conveniente. Finalmente, todos los planes se ejecutaron varias veces en el simulador para determinar su calidad media.
Los resultados hablan por sí mismos: la solución evolucionada superó tanto al propio plan de los expertos militares como al plan producido por sus modificaciones sobre la solución del AG. ``...Los planes producidos por los algoritmos automáticos tenían un rendimiento medio significativamente mayor al de los generados por los experimentados expertos militares'' (p. 161). Es más, los autores señalan que el plan del AG tenía sentido táctico. (Consistía en un ataque a dos flancos a la posición enemiga por pelotones de infantería mecanizada apoyados por helicópteros de ataque y exploradores terrestres, en conjunción con vehículos aéreos no tripulados realizando labores de reconocimiento para el fuego directo de artillería). Por añadidura, el plan evolucionado incluía unidades amigas individuales llevando a cabo misiones doctrinales -una propiedad emergente que apareció durante el curso de la ejecución, en lugar de ser especificada por el experimentador. En campos de batalla modernos, cada vez más conectados por red, el atractivo potencial de un algoritmo evolutivo que pueda automatizar la producción de planes tácticos de alta calidad debería ser obvio.
Naik 1996[48] informa de un uso interesante de los AGs en el cumplimiento de la ley, describiendo el software ``FacePrints'', un proyecto para ayudar a los testigos a identificar y describir a los sospechosos criminales. La imagen cliché del artista policía haciendo un dibujo del rostro del sospechoso en base a la descripción de los testigos es un método difícil e ineficiente: la mayoría de la gente no es buena describiendo aspectos individuales del rostro de una persona, como el tamaño de la nariz o la forma de la mandíbula, pero sin embargo son mejores al reconocer caras completas. FacePrints aprovecha esto utilizando un algoritmo genético que evoluciona dibujos de caras basándose en bases de datos de cientos de características individuales que pueden combinarse de infinitas maneras. El programa muestra a los testigos imágenes de rostros generadas aleatoriamente, y éstos escogen las que más se parecen a la persona que vieron; las caras seleccionadas mutan y se combinan para generar nuevas combinaciones de características, y el proceso se repite hasta que emerge un retrato preciso del rostro del sospechoso. En un caso real de atraco, los retratos definitivos que crearon los tres testigos eran sorprendentemente parecidos, y el dibujo resultante apareció en el periódico local.
En los seres vivos, las proteínas transmembrana son proteínas que sobresalen de una membrana celular. Las proteínas transmembrana realizan a menudo funciones importantes como detectar la presencia de ciertas sustancias en el exterior de la célula o transportarlas hacia el interior de la célula. Para comprender el comportamiento de una proteína transmembrana es necesario identificar el segmento de la proteína que realmente está insertado en la membrana, lo que se conoce como dominio transmembrana. Durante las dos últimas décadas, los biólogos moleculares han publicado una serie de algoritmos cada vez más precisos para este propósito.
Todas las proteínas utilizadas por los seres vivos están formadas por los mismos 20 aminoácidos. Algunos de estos aminoácidos son hidrofóbicos, lo que significa que repelen el agua, y algunos son hidrofílicos, lo que significa que atraen el agua. Las secuencias de aminoácidos que son parte de un dominio transmembrana tienen probabilidad de ser hidrofóbicas. Sin embargo, la hidrofobicidad no es una característica definida con precisión, y no existe acuerdo sobre una escala para medirla.
Koza et al. 1999[41], capítulo 16, utilizaron programación genética para diseñar un algoritmo que identificase el dominio transmembrana de una proteína. Se le suministró al programa genético un conjunto de operadores matemáticos estándares con los que trabajar, además de un conjunto de funciones booleanas para la detección de aminoácidos que devuelven +1 si el aminoácido de una posición dada es el aminoácido que detectan o -1 en caso contrario. (Por ejemplo, la función A? recibe como argumento un número que corresponde a una posición dentro de la proteína, y devuelve +1 si el aminoácido de esa posición es alanina, denotado por la letra A, y si no devuelve -1). Una variable de memoria compartida contenía una cuenta de la suma total, y cuando el algoritmo acababa, el segmento proteínico se identificaba como dominio transmembrana si su valor era positivo. Con tan sólo estas herramientas, ¿haría falta más información para que un diseñador humano produjese una solución eficiente a este problema?
Las aptitudes de las soluciones producidas por la programación genética fueron evaluadas probándolas con 246 segmentos proteínicos de los que se conocía su condición de transmembrana. Luego se evaluó al mejor individuo de la prueba con 250 casos adicionales inéditos (out-of-sample), y se comparó su efectividad con la de los cuatro mejores algoritmos humanos para el mismo propósito. El resultado: la programación genética produjo un algoritmo de identificación de segmentos transmembrana con una tasa total de error del 1,6%-significativamente menor que las de los cuatro algoritmos humanos, el mejor de los cuales tenía una tasa de error del 2,5%. El algoritmo diseñado genéticamente, al que los autores llamaron regla 0-2-4, funciona de la manera siguiente:
La competición en la industria actual de las telecomunicaciones es feroz, y se ha acuñado un nuevo término -``fuga''1- para describir la velocidad a la que los usuarios se cambian de un proveedor de servicios a otro. La fuga le cuesta a las compañías de telecomunicaciones una gran cantidad de dinero cada año, y reducir las fugas es un factor importante para aumentar la rentabilidad. Si las compañías pueden contactar con los clientes que tienen probabilidad de cambiar y ofrecerles incentivos especiales para que se queden, puede reducirse la tasa de fugas; pero ninguna compañía tiene los recursos para contactar a más de un pequeño porcentaje de sus clientes. El problema es, por tanto, cómo identificar a los clientes que más piensen fugarse con mayor probabilidad. Todas las compañías tienen grandes bases de datos con información de los clientes que teóricamente puede utilizarse para este propósito; pero ¿qué método funciona mejor para examinar esta enorme cantidad de datos e identificar los sutiles patrones y tendencias que indican la probabilidad de fuga de un cliente?
Au, Chan y Yao 2003[7] aplicaron algoritmos genéticos a este problema para generar un conjunto de reglas de tipo si-entonces para predecir la probabilidad de fuga de distintos grupos de clientes. En su AG, la primera generación de reglas, todas las cuales tenían una condición, fue generada utilizando una técnica de inducción probabilística. Las generaciones posteriores las refinaron, combinando sencillas reglas de una condición con reglas más complejas con varias condiciones. Para la medición de la aptitud se utilizó una medida de correlación objetiva de la ``interesantitud'', que no necesitaba información de entrada subjetiva. El algoritmo evolutivo de explotación de datos se probó sobre una base de datos real de 100.000 clientes proporcionada por una compañía malasia, y su rendimiento se comparó con el de dos métodos alternativos: una red neuronal multicapa y un algoritmo basado en árbol de decisiones ampliamente utilizado, el C4.5. Los autores afirman que su AE fue capaz de descubrir regularidades ocultas en la base de datos y ``fue capaz de hacer predicciones precisas de fuga con distintas tasas de fuga'' (p. 542), superando al C4.5 bajo todas las circunstancias, superando a la red neuronal en tasas mensuales de fuga bajas e igualándola en tasas de fuga mayores y, en ambos casos, alcanzando las conclusiones más rápidamente. Algunas ventajas más del enfoque evolutivo son que puede funcionar eficientemente incluso cuando faltan algunos campos de datos, y que puede expresar sus descubrimientos en conjuntos de reglas fácilmente comprensibles, al contrario que la red neuronal.
Entre algunas de las reglas más interesantes halladas por el AE se encuentran las siguientes: los clientes tienen más probabilidad de fugarse si se han suscrito personalmente al plan de servicios y no han sido admitidos en ningún plan de bonificación (una solución potencial sería admitir a todos esos clientes en planes de bonificación); los clientes tienen más probabilidad de fugarse si viven en Kuala Lumpur, tienen entre 36 y 44 años y pagan sus facturas en efectivo (supuestamente porque es más fácil cambiarse de proveedor para los clientes que pagan al contado, a diferencia de los que cargan en cuenta automáticamente); y los clientes que viven en Penang y contrataron a través de un cierto vendedor tienen más probabilidades de fugarse (este vendedor puede estar proporcionando un mal servicio al cliente y debería ser investigado).
Rizki, Zmuda y Tamburino 2002[53] utilizaron algoritmos evolutivos para evolucionar un complejo sistema de reconocimiento de patrones con una amplia variedad de usos potenciales. Los autores señalan que el reconocimiento de patrones es una tarea cada vez más realizada por algoritmos de aprendizaje automático, en particular, algoritmos evolutivos. La mayoría de ellos comienzan con un acervo de características predefinidas, del que un AE puede seleccionar combinaciones apropiadas para la tarea en cuestión; en contraste, este método empezaba desde cero, primero evolucionando detectores individuales de característica en forma de árboles de expresiones, y luego evolucionando combinaciones cooperativas de esos detectores para producir un sistema completo de reconocimiento de patrones. El proceso evolutivo selecciona automáticamente el número de detectores de característica, la complejidad de los detectores y los aspectos específicos de los datos a los que responde cada detector.
Para probar su sistema, los autores le asignaron la tarea de clasificar aviones basándose en sus reflexiones rádar. Un mismo tipo de avión puede devolver señales bastante distintas dependiendo del ángulo y elevación desde el que se le observa, y distintos tipos de avión pueden devolver señales muy parecidas, así que esto no es una tarea trivial. El sistema de reconocimiento de patrones evolucionado clasificó correctamente un 97,2% de los objetivos, un porcentaje neto mayor que el de las otras tres técnicas -una red neuronal perceptrón, un algoritmo clasificador KNN y un algoritmo de base radial- con las que fue comparado. (La precisión de la red de base radial era sólo un 0,5% menor que la del clasificador evolucionado, una diferencia que no es estadísticamente significativa, pero la red de base radial necesitó 256 detectores de característica mientras que el sistema reconocedor evolucionado sólo utilizó 17). Como afirman los autores, ``los sistemas de reconocimiento que evolucionan utilizan menos características que los sistemas producidos utilizando técnicas convencionales, pero consiguen una precisión de reconocimiento comparable o superior'' (p. 607). También se han aplicado varios aspectos de su sistema en problemas que incluyen el reconocimiento óptico de caracteres, la revisión industrial y el análisis médico de imágenes.
Hughes y Leyland 2000[37] también aplicaron AGs multiobjetivo a la tarea de clasificar objetivos basándose en sus reflexiones rádar. Los datos de una sección transversal rádar de alta resolución necesitan enormes cantidades de espacio de almacenamiento en disco, y producir un modelo realista de la fuente a partir de los datos es muy costoso computacionalmente. En contraste, el método basado en el AG de los autores demostró ser muy exitoso, produciendo un modelo tan bueno como el del método iterativo tradicional, pero reduciendo el gasto computacional y las necesidades de almacenamiento hasta el punto de que era factible generar buenos modelos en un ordenador de escritorio. En contraste, el método iterativo tradicional requiere diez veces más resolución y 560.000 veces más accesos a los datos de imagen para producir modelos de calidad similar. Los autores concluyen que sus resultados ``demuestran claramente'' (p. 160) la capacidad del AG de procesar datos de rádar bidimensionales y tridimensionales de cualquier nivel de resolución con muchos menos cálculos que los métodos tradicionales, manteniendo una precisión aceptablemente alta.
El torneo internacional RoboCup es un proyecto para promocionar el avance de la robótica, la inteligencia artificial y los campos relacionados, proporcionando un problema estándar con el que probar las nuevas tecnologías -concretamente, es un campeonato anual de fútbol entre equipos de robots autónomos. (El objetivo fijado es desarrollar un equipo de robots humanoides que puedan vencer al equipo humano de fútbol que sea campeón del mundo en 2050; actualmente, la mayoría de los equipos de robots participantes funcionan con ruedas). Los programas que controlan a los miembros del equipo robótico deben exhibir un comportamiento complejo, decidiendo cuándo bloquear, cuándo tirar, cómo moverse, cuándo pasar la pelota a un compañero, cómo coordinar la defensa y el ataque, etcétera. En la liga simulada de 1997, David Andre y Astro Teller inscribieron a un equipo llamado Darwin United cuyos programas de control habían sido desarrollados automáticamente desde cero mediante programación genética, un desafío a la creencia convencional de que ``este problema es simplemente demasiado difícil para una técnica como ésa'' (Andre y Teller 1999[3], p. 346).
Para resolver este difícil problema, Andre y Teller le proporcionaron al programa genético un conjunto de funciones de control primitivas como girar, moverse, tirar, etcétera. (Estas funciones estaban también sujetas al cambio y refinamiento durante el curso de la evolución). Su función de aptitud, escrita para que recompensara el buen juego en general en lugar de marcar goles expresamente, proporcionaba una lista de objetivos cada vez más importantes: acercarse a la pelota, golpear la pelota, conservar la pelota en el campo contrario, moverse en la dirección correcta, marcar goles y ganar el partido. Debe señalarse que no se suministró ningún código para enseñar específicamente al equipo cómo conseguir estos objetivos complejos. Luego los programas evolucionados se evaluaron utilizando un modelo de selección jerárquico: en primer lugar, los equipos candidatos se probaron en un campo vacío y, si no marcaban un gol en menos de 30 segundos, se rechazaban. Luego se evaluaron haciéndoles jugar contra un equipo estacionario de ``postes pateadores'' que golpeaban la pelota hacia el campo contrario. En tercer lugar, el equipo jugaba un partido contra el equipo ganador de la competición RoboCup de 1997. Finalmente, los equipos que marcaron al menos un gol contra este equipo jugaron unos contra otros para determinar cuál era el mejor.
De los 34 equipos de su división, Darwin United acabó en decimoséptima posición, situándose justo en el medio de la clasificación y superando a la mitad de los participantes escritos por humanos. Aunque una victoria en el torneo sin duda habría sido más impresionante, este resultado es competitivo y significante de pleno derecho, y lo parece aún más a la luz de la historia. Hace unos 25 años, los programas informáticos que jugaban al ajedrez estaban en su infancia; por primera vez, una computadora había sido inscrita recientemente en una competición regional, aunque no ganó (Sagan 1979[55], p. 286). Pero ``una máquina que juega al ajedrez a un nivel medio de la capacidad humana es una máquina muy capaz'' (ibid.), y podría decirse que lo mismo es cierto para el fútbol robotizado. Si las máquinas de ajedrez actuales compiten al nivel de los grandes maestros, ¿qué tipo de sistemas producirá la programación genética dentro de 20 o 30 años?
Burke y Newall 1999[11] utilizaron algoritmos genéticos para diseñar los horarios de los exámenes universitarios. Se sabe que, en general, el problema del horario es NP-completo, lo que significa que no se conoce un método para hallar con garantías una solución óptima en un tiempo razonable. En un problema así, hay restricciones duras -no puede asignarse el mismo aula a dos exámenes a la vez- y restricciones suaves -si es posible, no deben asignarse varios exámenes en sucesión a un mismo estudiante, para minimizar la fatiga. Las restricciones duras deben satisfacerse, mientras que las restricciones suaves deben satisfacerse lo máximo posible. Los autores llaman ``algoritmo memético'' a su método híbrido para resolver este problema: un algoritmo evolutivo con selección por rango proporcional a la aptitud, combinado con un trepacolinas local para optimizar las soluciones halladas por el AE. El AE se utilizó en cuatro conjuntos de datos de universidades reales (la menor de las cuales tenía 25.000 alumnos), y sus resultados se compararon con los resultados producidos por un método heurístico de vuelta atrás, un algoritmo muy consolidado que se encuentra entre los mejores que se conocen para este problema y que se utiliza en varias universidades. Comparado con este método, el AE produjo un resultado con una reducción de la penalización bastante uniforme del 40%.
He y Mort 2000[35] aplicaron algoritmos genéticos al problema de hallar rutas óptimas en las redes de telecomunicaciones (como las redes de telefonía e Internet), que se usan para transmitir datos desde los remitentes hasta los destinatarios. Esto es un problema NP-difícil, un tipo de problema para el que los AGs son ``extremadamente aptos... y han encontrado una enorme variedad de aplicaciones exitosas en esos campos'' (p. 42). Es además un problema multiobjetivo, en el que hay que equilibrar objetivos en conflicto como maximizar el caudal de datos, minimizar los retrasos en la transmisión y la pérdida de datos, encontrar caminos de bajo coste y distribuír la carga uniformemente entre los encaminadores o conmutadores de la red. Cualquier algoritmo real satisfactorio debe también ser capaz de redirigir el tráfico de las rutas principales que fallen o estén congestionadas.
En el AG híbrido de los autores se utilizó un algoritmo de tipo ``primero el camino más corto'', que minimiza el número de ``saltos'' que debe realizar un paquete de datos dado, para generar la semilla de la población inicial. Sin embargo, esta solución no tiene en cuenta la congestión o fallo de los enlaces, condiciones inevitables en redes reales, y es entonces cuando el AG toma el control, intercambiando secciones de rutas. Cuando se probó sobre un conjunto de datos derivado de una base de datos en red real de Oracle, se descubrió que el AG era capaz de redirigir enlaces rotos o congestionados, equilibrar la carga de tráfico y maximizar el caudal total de la red. Los autores afirman que estos resultados demuestran la ``efectividad y escalabilidad'' del AG y que ``se pueden conseguir soluciones óptimas o casi óptimas'' (p. 49).
Esta técnica ha encontrado aplicaciones reales para propósitos similares, como informan Begley y Beals 1995[9]. La compañía de telecomunicaciones U.S. West (ahora fusionada con Qwest) se enfrentó a la tarea de desplegar una red de fibra óptica. Hasta hace poco, el problema de diseñar la red para minimizar la longitud total de cable desplegado era resuelto por un ingeniero experimentado; ahora la compañía utiliza un algoritmo genético para realizar la tarea automáticamente. Los resultados: ``El tiempo de diseño para las redes nuevas ha caído de dos meses a dos días, y le supone un ahorro a U.S. West de 1 millón a 10 millones de dólares cada una'' (p. 70).
Jensen 2003[38] y Chryssolouris y Subramaniam 2001[16] aplicaron algoritmos genéticos a la tarea de generar programas para líneas de montaje (job shop scheduling). Éste es un problema de optimización NP-difícil con múltiples criterios: deben tomarse en cuenta factores como el coste, los retrasos y el rendimiento, y puede que se tenga que cambiar al vuelo el programa de la línea de montaje debido a averías en la maquinaria, ausencia de empleados, retrasos en la entrega de piezas, y otras complicaciones, lo que hace que la robustez del programa sea una consideración importante. Ambos artículos concluyen que los AGs son significativamente superiores a las reglas de despacho de prioridad utilizadas comúnmente, al producir programas eficientes que pueden tratar con más facilidad los retrasos y las averías. Estos resultados no son simplemente teóricos, sino que se han aplicado a situaciones reales:
Como informa Naik 1996[48], los organizadores de los Juegos Paraolímpicos de 1992 utilizaron un AG para diseñar los horarios de los eventos. Como informa Petzinger 1995[50], John Deere & Co. ha utilizado AGs para generar los programas de montaje para una planta de Moline, Illinois, que fabrica plantadoras y otras maquinarias agrícolas pesadas. Al igual que los coches de lujo, éstas pueden construírse en una gran variedad de configuraciones con muchas partes y opciones distintas, y la enorme cantidad de maneras posibles de construirlas implica que el diseño eficiente de programas de montaje sea un problema aparentemente intratable. La productividad se veía mermada por cuellos de botella en el montaje, los equipos de trabajadores discutían, y se estaba perdiendo dinero. Finalmente, en 1993, Deer acudió a Bill Fulkerson, un analista e ingeniero de personal que concibió la utilización de un algoritmo genético para producir programas de montaje para la planta. Tras superar el escepticismo inicial, el AG demostró su valía rápidamente: la producción mensual aumentó un 50 por ciento, el tiempo extra casi desapareció y otras plantas de Deere están incorporando los AGs en sus propios diseños de programas de montaje.
Como informa Rao 1998[52], Volvo ha utilizado un programa evolutivo llamado OptiFlex para diseñar el programa de montaje de su fábrica de Dublín, Virginia, de un millón de metros cuadrados, una tarea que requiere controlar cientos de restricciones y millones de permutaciones posibles para cada vehículo. Como todos los algoritmos genéticos, OptiFlex funciona combinando aleatoriamente distintos programas de montaje posibles, determinando su aptitud clasificándolos en base a sus costos, beneficios y restricciones, y luego haciendo que las mejores soluciones intercambien genes entre ellas y vuelvan a la población para otra prueba. Hasta hace poco, esta desalentadora tarea era responsabilidad de un ingeniero humano, al que le llevaba hasta cuatro días producir el programa para cada semana; ahora, gracias a los AGs, esta tarea se puede completar en un día con una mínima intervención humana.
Como informa Lemley 2001[45], United Distillers and Vintners, una empresa escocesa que es el mayor y más rentable distribuidor de licores del mundo y es responsable de más de un tercio de la producción mundial de whisky de grano, utiliza un algoritmo genético para administrar su inventario y sus suministros. Esto es una tarea desalentadora que exige almacenar y distribuír eficientemente más de 7 millones de barriles, que contienen 60 recetas distintas, entre un enorme sistema de almacenes y destilerías, dependiendo de una multitud de factores como la edad, el número de malta, el tipo de madera y las condiciones del mercado. Anteriormente, coordinar este complejo flujo de suministro y demanda requería de cinco empleados a tiempo completo. Hoy, unas cuantas pulsaciones de teclado en un ordenador solicitan a un algoritmo genético que genere un programa cada semana, y la eficiencia de almacenamiento casi se ha duplicado.
Beasley, Sonander y Havelock 2001[8] utilizaron un AG para programar los aterrizajes del London Heathrow, el aeropuerto más transitado del Reino Unido. Esto es un problema multiobjetivo que implica, entre otras cosas, minimizar los retrasos y maximizar el número de vuelos mientras se mantiene la suficiente distancia de separación entre los aviones (los vórtices de aire que se forman en la estela de un avión pueden ser peligrosos para otro avión que vuele demasiado cerca). Comparado con los horarios reales de un periodo intensivo del aeropuerto, el AG fue capaz de reducir el tiempo de espera medio en un 2-5%, implicando dos o tres vuelos extra despegando y aterrizando por cada hora -una mejora significativa. Sin embargo, se han logrado mejoras mayores: como se informa en Wired 2002[1], aeropuertos internacionales y líneas aéreas importantes como Heatrhow, Toronto, Sydney, Las Vegas, San Francisco, America West Airlines, AeroMexico y Delta Airlines están utilizando algoritmos genéticos para programar los despegues, aterrizajes, mantenimiento y otras tareas, mediante el software del Ascent Technology's SmartAirport Operations Center (ver http://www.ascent.com/faq.html). Cruzando y mutando las soluciones en forma de horarios que incorporan miles de variables, ``Ascent vence con comodidad a los humanos, aumentando la productividad hasta en un 30 por ciento en todos los aeropuertos en los que se ha implementado''.
Benini y Toffolo 2002[10] aplicaron un algoritmo genético a la tarea multiobjetivo de diseñar molinos eólicos para generar energía eléctrica. Este diseño ``es un procedimiento complejo caracterizado por varias decisiones sobre contrapartidas... El proceso de toma de decisiones es muy difícil y no hay tendencias de diseño bien establecidas'' (p. 357); como resultado, hoy existen varios tipos de turbina distintos y no hay acuerdo sobre cuál es la óptima, si alguna lo es. Deben tomarse en cuenta objetivos mutuamente exclusivos como la producción máxima de energía anual y el coste mínimo de la energía. En este artículo se utilizó un algoritmo evolutivo multiobjetivo para encontrar el mejor conjunto de contrapartidas entre estos objetivos, construyendo palas de molino con una configuración óptima de características como la velocidad de la punta de la pala, la razón buje/punta, y la distribución de cuerda y giro. Al final, al AG consiguió encontrar soluciones competitivas con los diseños comerciales, además de dilucidar más claramente los márgenes entre los que se puede aumentar la producción anual de energía sin producir diseños demasiado caros.
Haas, Burnham y Mills 1997[32] utilizaron un algoritmo genético multiobjetivo para optimizar la forma, orientación e intensidad del haz de los emisores de rayos X utilizados en la radioterapia dirigida, para destruír los tumores cancerosos al tiempo que se evita el tejido sano. (Los fotones de rayos X dirigidos hacia un tumor tienden a dispersarse por las estructuras interiores del cuerpo, dañando inintencionadamente los órganos internos. El reto consiste en minimizar este efecto mientras se maximiza la dosis de radiación dirigida hacia el tumor). Utilizando un modelo de aptitud basada en rango, los investigadores comenzaron con la solución producida por el método convencional, un método de mínimos cuadrados iterativo, y luego utilizaron el AG para modificarlo y mejorarlo. Construyendo un modelo del cuerpo humano y exponiéndolo al rayo evolucionado por el AG, encontraron un buen acuerdo entre las distribuciones de radiación predichas y reales. Los autores concluyen que sus resultados ``muestran una protección [de los órganos sanos] que no podía lograrse utilizando las técnicas convencionales'' (p. 1745).
Lee y Zak 2002[44] utilizaron un algoritmo genético para evolucionar un conjunto de reglas para controlar un sistema de frenos antibloqueo automovilístico. Aunque la capacidad que tienen los sistemas de freno antibloqueo de reducir la distancia de frenada y mejorar la maniobrabilidad ha salvado muchas vidas, el rendimiento del ABS depende de las condiciones de la superficie de la carretera: por ejemplo, un controlador ABS que esté optimizado para el asfalto seco no funcionará igual de bien en carreteras mojadas o heladas, y viceversa. En este artículo, los autores proponen un AG para ajustar un controlador ABS que pueda identificar las propiedades de la superficie de la carretera (monitorizando el patinaje y aceleración de las ruedas) y pueda actuar en consecuencia, liberando la cantidad adecuada de fuerza de frenado para maximizar la tracción de las ruedas. En las pruebas, el ABS puesto a punto genéticamente ``exhibe características de rodada excelentes'' (p. 206) y fue ``muy superior'' (p. 209) a los otros dos métodos de maniobras de frenado, encontrando con rapidez nuevos valores óptimos para el patinaje de las ruedas cuando cambia el tipo de terreno bajo un coche en movimiento, y reduciendo la distancia total de frenada. ``La lección que hemos aprendido de nuestro experimento... es que un AG puede ayudar a ajustar incluso un controlador bien diseñado. En nuestro caso, ya teníamos una buena solución del problema; sin embargo, con la ayuda de un AG, conseguimos mejorar significativamente la estrategia de control. En resumen, parece que merece la pena intentar aplicar un AG incluso en un controlador bien diseñado, porque hay muchas probabilidades de que se pueda hallar una configuración del controlador mejor utilizando AGs'' (p. 211).
Como cita Schechter 2000[59], el Dr. Peter Senecal, de la Universidad de Wisconsin, utilizó algoritmos genéticos de población pequeña para mejorar la eficiencia de los motores diésel. Estos motores funcionan inyectando combustible en una cámara de combustión que está llena de aire extremadamente comprimido, y por tanto extremadamente caliente, lo bastante caliente para hacer que el combustible explote y empuje un pistón que produce la fuerza motriz del vehículo. Este diseño básico ha cambiado poco desde que Rudolf Diesel lo inventó en 1893; aunque se ha empleado mucho esfuerzo en realizar mejoras, es una tarea muy difícil de realizar analíticamente, porque requiere un conocimiento preciso del comportamiento turbulento que exhibe la mezcla de combustible y aire, y de la variación simultánea de muchos parámetros independientes. Sin embargo, el método de Senecal prescindía de ese conocimiento específico del problema y, en cambio, funcionaba evolucionando parámetros como la presión de la cámara de combustión, los tiempos de inyección de combustible y la cantidad de combustible de cada inyección. El resultado: la simulación produjo un motor mejorado que consumía un 15% menos de combustible que un motor diesel normal y producía dos tercios menos de óxido nítrico de escape y la mitad de hollín. Luego el equipo de Senecal construyó un motor diésel real de acuerdo con las especificaciones de la solución evolucionada, y obtuvieron los mismos resultados. Ahora Senecal sigue su trabajo evolucionando la geometría del propio motor, lo que con suerte producirá todavía más mejoras.
Como citan Begley y Beals 1995[9], Texas Instruments utilizó un algoritmo genético para optimizar la disposición de los componentes de un chip informático, colocando las estructuras de manera que se minimice el área total para crear un chip lo más pequeño posible. Utilizando una estrategia de conexiones que no se le había ocurrido a ningún humano, el AG alcanzó un diseño que ocupaba un 18% menos de espacio.
Finalmente, como cita Ashley 1992[5], empresas de la industria aeroespacial, automovilística, fabril, turbomaquinaria y electrónica están utilizando un sistema de software propietario conocido como Engineous, que utiliza algoritmos genéticos, para diseñar y mejorar motores, turbinas y otros dispositivos industriales. En palabras de su creador, el Dr. Siu Shing Tong, Engineous es ``un maestro `toqueteador', ensayando incansablemente las puntuaciones de escenarios de tipo ``y-si'' hasta que emerge la mejor solución posible'' (p. 49). En un ensayo del sistema, Engineous consiguió producir un incremento del 0,92 por ciento de la eficiencia de una turbina experimental en sólo una semana, mientras que diez semanas de trabajo de un diseñador humano sólo produjeron un 0,5 por ciento de mejora.
Supuestamente, Engineous no sólo cuenta con algoritmos genéticos; también emplea técnicas de optimización numérica y sistemas expertos que utilizan reglas si-entonces para imitar el proceso de toma de decisiones de un ingeniero humano. Sin embargo, estas técnicas dependen mucho de información específica del dominio, carecen de aplicabilidad general, y son propensas a quedar atrapadas en óptimos locales. En contraste, el uso de algoritmos genéticos permite a Engineous explorar regiones del espacio de búsqueda que pasan por alto los otros métodos.
Engineous ha obtenido un amplio uso en una gran variedad de industrias y problemas. El más famoso fue cuando se utilizó para mejorar la turbina generadora de energía del avión Boeing 777; como informan Begley y Beals 1995[9], el diseño optimizado genéticamente era casi un 1% más eficiente en combustible que los motores anteriores, lo que en un campo como éste es una ganancia caída del cielo. Engineous también se ha utilizado para optimizar la configuración de motores eléctricos industriales, generadores hidroeléctricos y turbinas de vapor, para proyectar redes eléctricas, y para diseñar generadores superconductores y generadores de energía nuclear para satélites en órbita. Rao 1998[52] informa también de que la NASA ha utilizado Engineous para optimizar el diseño de un avión de gran altitud para analizar la disminución del ozono, que debe ser a la vez ligero y eficiente.
Como era de esperar, la demostración real del poder de la evolución que representan los AGs ha resultado sorprendente y descorcentante para los creacionistas, que siempre han afirmado que sólo un diseño inteligente, no la variación aleatoria y la selección, puede haber producido la cantidad y complejidad de información que contienen los seres vivos. Por tanto, han argumentado que el éxito de los algoritmos genéticos no nos permite deducir nada sobre la evolución biológica. Abordaré las críticas de dos antievolucionistas que representan dos puntos de vista distintos: un creacionista de tipo tierra-joven, el Dr. Don Batten, de ``Answers in Genesis'', que ha escrito un artículo titulado ``Algoritmos genéticos - ¿demuestran que la evolución funciona?'', y un creacionista de tipo tierra-vieja y defensor del diseño inteligente, el Dr. William Dembski, cuyo reciente libro ``No Free Lunch'' (Dembski 2002[21]) trata sobre este tema.
Batten afirma que los AGs deben ser cuantitativos, de manera que se pueda seleccionar cualquier mejora. Esto es cierto. Luego continua diciendo: ``Muchos caracteres biológicos son cualitativos -o funcionan o no funcionan, así que no existe una manera de llegar paso a paso de la ausencia de función a la función''. Sin embargo, esta aseveración no ha sido demostrada, y no está apoyada por la evidencia. Batten ni siquiera intenta ofrecer un ejemplo de caracter biológico que ``o funciona o no funciona'', y por tanto no pueda construirse paso a paso.
Pero aunque hubiera ofrecido tal ejemplo de caracter, ¿cómo podría demostrar razonablemente que no hay un camino paso a paso hasta él? Aunque no conozcamos tal camino, ¿significa eso que no existe ninguno? Por supuesto que no. Batten afirma efectivamente que si no entendemos cómo han evolucionado ciertos caracteres, entonces es imposible que esos caracteres hayan evolucionado -un ejemplo clásico de la falacia lógica elemental del argumento de la ignorancia. El espacio de búsqueda de todas las posibles variantes de cualquier caracter biológico dado es enorme, y en la mayoría de los casos nuestro conocimiento supone tan sólo una fracción infinitesimal de todas las posibilidades. Perfectamente pueden existir numerosos caminos hacia una estructura de los que no conozcamos nada todavía; no hay ninguna razón en absoluto para creer que nuestra ignorancia actual establece límites a nuestro progreso futuro. De hecho, la historia nos da razones para estar seguros de esto: los científicos han hecho enormes progresos para explicar la evolución de muchas estructuras y sistemas biológicos complejos, tanto macroscópicos como microscópicos (por ejemplo, vea estas páginas sobre la evolución de sistemas moleculares complejos, genes ``reloj'', la lengua del pájaro carpintero o el escarabajo bombardero). Tenemos justificación para creer probable que los que nos han eludido hasta ahora también se entenderán con claridad en el futuro.
De hecho, los propios AGs nos ofrecen una excelente razón para suponer esto. Muchos de los problemas en los que se han aplicado son problemas complejos de ingeniería y diseño de los que no se conocía la solución previamente, y por lo tanto el problema no podía ``amañarse'' para facilitar el éxito del algoritmo. Si los creacionistas tuvieran razón, habría sido completamente razonable esperar que los algoritmos genéticos hubieran fallado estrepitosamente una y otra vez al ser aplicados a estos problemas, pero, en cambio, ha ocurrido justo lo contrario: los AGs han descubierto soluciones poderosas y de gran calidad a problemas difíciles en una gran variedad de campos. Esto pone seriamente en duda incluso si existen problemas como los que Batten describe, cuyas soluciones sean inaccesibles a un proceso evolutivo.
Batten afirma que, en los AGs, ``se selecciona un caracter individual, mientras que cualquier ser vivo es multidimensional'', y afirma que en los seres vivos con cientos de caracteres, ``la selección tiene que operar con todos los caracteres que afecten a la supervivencia'', mientras que ``[un] AG no funciona con tres o cuatro objetivos diferentes, o me atrevería a decir que ni siquiera con dos''.
Este argumento revela la profunda ignorancia de Batten sobre la literatura relevante. Tan sólo un vistazo superficial del trabajo realizado con algoritmos evolutivos (o un vistazo a la sección anterior de este ensayo) habría revelado que los algoritmos genéticos multiobjetivo son un campo de investigación importante y floreciente dentro del más amplio campo de la computación evolutiva, y le habría evitado realizar una afirmación tan embarazosamente incorecta. Existen artículos de revista, números enteros de revistas prominentes sobre computación evolutiva, conferencias enteras y libros enteros sobre el tema de los AGs multiobjetivo. Coello 2000[18] proporciona una recopilación muy extensa, con cinco páginas de referencias a artículos sobre el uso de algoritmos genéticos multiobjetivo en una amplio abanico de campos; vea también Fleming y Purshouse 2002[22]; Hanne 2000[33]; Zitzler y Thiele 1999[65]; Fonseca y Fleming 1995[23]; Srinivas y Deb 1994[60]; Goldberg 1989[29], p. 197. Sobre el uso de AGs multiobjetivo para resolver problemas específicos, vea los libros y artículos: Obayashi et al. 2000[49]; Sasaki et al. 2001[57]; Benini y Toffolo 2002[10]; Haas, Burnham y Mulls 1997[32]; Chryssolouris y Subramaniam 2001[16]; Hughes y Leyland 2000[37]; He y Mort 2000[35]; Kewley y Embrechts 2002[39]; Beasley, Sonander y Havelock 2001[8]; Sato et al. 2002[58]; Tang et al. 1996[62]; Williams, Crossley y Lang 2001[64]; Koza et al. 1999[41]; Koza et al. 2003[42]. Vea un repositorio extenso de referencias sobre AGs multiobjetivo en http://www.lania.mx/ccoello/EMOO.
Batten afirma que, en los AGs, ``siempre sobrevive algo para mantener el proceso'', mientras que esto no es necesariamente cierto en el mundo real -en resument, los AGs no permiten la posibilidad de una extinción.
Sin embargo, esto no es cierto; la extinción puede ocurrir. Por ejemplo, algunos AGs utilizan un modelo de selección con umbral en el que los individuos deben tener una aptitud superior a un nivel predeterminado para poder sobrevivir y reproducirse (Haupt y Haupt 1998[34], p. 37). Si no hay ningún individuo que cumpla este criterio en este tipo de AG, la población puede extinguirse efectivamente. Pero incluso en AGs que no establecen umbrales pueden ocurrir estados análogos a la extinción. Si las tasas de mutación son demasiado altas o las presiones selectivas demasiado fuertes, un AG nunca encontrará una solución factible. La población puede acabar en un caos sin remedio al verse afectados los cantidatos aptos por el hecho de que las mutaciones perjudiciales se desarrollen con más rapidez de la que la selección puede eliminarlas (catástrofe de errores), o puede retorcerse inútilmente, incapaz de conseguir ningún aumento de la aptitud lo bastante grande para que pueda ser seleccionado. Al igual que en la naturaleza, debe haber un equilibrio o nunca se alcanzará una solución. La ventaja que tiene un programador a este respecto es que, si ocurre esto, él puede introducirle al programa valores diferentes -para el tamaño de la población, para la tasa de mutación, para la presión selectiva- y comenzar de nuevo. Obviamente, esto no es una opción para los seres vivos. Batten dice que ``no existe una regla en la evolución que diga que algunos organismos de la población que evoluciona permanecerán viables ocurran las mutaciones que ocurran'', pero tampoco existe una regla así en los algoritmos genéticos.
Batten también afirma que ``los AGs que he observado preservan artificialmente a los mejores de la generación anterior y los protegen de las mutaciones o la recombinación, en caso de que no se produzca algo mejor en la siguiente generación''. Abordaré esta crítica en el siguiente punto.
La siguiente afirmación de Batten es que los AGs ignoran el ``dilema de Haldane'', que dice que un alelo que contribuya menos a la aptitud de un organismo tardará correspondientemente más tiempo en fijarse en la población. Obviamente, a lo que se refiere es a la técnica de selección elitista, que selecciona automáticamente al mejor candidato de cada generación sin importar lo pequeña que sea su ventaja sobre sus competidores. Tiene razón al sugerir que, en la naturaleza, las ventajas competitivas muy pequeñas pueden tardar en propagarse mucho más. Los algoritmos genéticos no son un modelo exacto de la evolución biológica a este respecto.
Sin embargo, esto no viene al caso. La selección elitista es una idealización de la evolución biológica -un modelo de lo que pasaría en la naturaleza si de vez en cuando no interviniese el azar. Como reconoce Batten, el dilema de Haldane no afirma que una mutación ligeramente ventajosa nunca quedará fijada en una población; afirma que tardará más en hacerlo. Sin embargo, cuando el tiempo de computación está muy demandado o cuando un investigador de AGs desea obtener una solución con mayor rapidez, puede ser deseable saltarse este proceso implementando el elitismo. Un punto importante es que el elitismo no afecta a qué mutaciones surgen, sólo asegura la selección de las mejores que surjan. No importaría lo fuerte que fuera la selección si no ocurrieran mutaciones que incrementasen la información. En otras palabras, el elitismo acelera la convergencia una vez que se ha descubierto una solución buena -no provoca un resultado que no habría ocurrido de otra manera. Por lo tanto, si los algoritmos genéticos con elitismo pueden producir información nueva, entonces también lo puede hacer la evolución en la naturaleza.
Además, no todos los AGs utilizan selección elitista. Muchos no lo hacen, y en cambio dependen sólo de selección por ruleta de rueda y otras técnicas de muestreo estocásticas, con no menor éxito. Por ejemplo, Koza et al 2003[42], p. 8-9, proporciona ejemplos de 36 casos en los que la programación genética ha producido resultados competitivos con los de los humanos, incluyendo la recreación automática de 21 inventos patentados con anterioridad (seis de los cuales fueron patentados durante o después de 2000), 10 de los cuales duplican la funcionalidad de la patente de manera diferente, e incluyendo además dos nuevos inventos patentables y cinco algoritmos nuevos que superan a cualquier algoritmo humano escrito para el mismo propósito. Como declara el Dr. Koza en una referencia anterior al mismo trabajo (1999[41], p. 1.070): ``No se utiliza la estrategia elitista''. Algunos artículos más citados en este ensayo, en los que no se utiliza el elitismo: Robin et al. 2003[54]; Rizki, Zmuda y Tamburino 2002[53]; Chryssolouris y Subramaniam 2001[16]; Burke y Newall 1999[11]; Glen y Payne 1995[28]; Au, Chan y Yao 2003[7]; Jensen 2003[38]; Kewley y Embrechts 2002[39]; Williams, Crossley y Lang 2001[64]; Mahfoud y Mani 1996[46]. En todos estos casos, sin ningún mecanismo para asegurar que se seleccionaban los mejores individuos de cada generación, sin eximir a estos individuos del potencial cambio aleatorio perjudicial, los algoritmos genéticos siguen produciendo resultados poderosos, eficientes y competitivos con los resultados humanos. Este hecho puede ser sorprendente para creacionistas como Batten, pero es algo completamente esperado para los defensores de la evolución.
Esta crítica es confusa. Batten afirma que una generación puede durar microsegundos en un AG, mientras que en los seres vivos una generación puede durar desde minutos hasta años. Esto es cierto, pero no explica cómo influye esto en la validez de los AGs como evidencia para la evolución. Si un AG puede generar información nueva, tarde el tiempo que tarde, entonces la evolución natural puede hacer lo mismo sin duda; que los AGs pueden efectivamente hacerlo es todo lo que trata de demostrar este ensayo. La única cuestión restante sería entonces si la evolución biológica ha tenido realmente el tiempo necesario para causar un cambio significativo, y la respuesta a esta cuestión está a cargo de los biólogos, geólogos y físicos, no de los programadores informáticos.
Sin embargo, la respuesta que han proporcionado estos científicos está en completo acuerdo con las escalas de tiempo evolutivas. Numerosas líneas independientes de evidencia, incluyendo la datación isocrónica radiométrica, los ritmos de enfriamiento de las enanas blancas, la no existencia en la naturaleza de isótopos con tiempos cortos de semideintegración, los ritmos de alejamiento de las galaxias lejanas, y el análisis de la radiación cósmica de fondo, convergen hacia la misma conclusión: una Tierra y un universo con muchos miles de millones de años, sin duda tiempo suficiente para que la evolución haya producido toda la diversidad de vida que observamos hoy para todas las estimaciones razonables.
Batten afirma, sin proporcionar ninguna evidencia o referencia que le apoye, que los AGs ``producen comúnmente cientos o miles de `descendientes' por generación'', un ritmo que ni siquiera las bacterias, los organismos biológicos que se reproducen con mayor velocidad, pueden igualar.
Esta crítica erra el tiro de varias maneras. Primero, si la métrica que se utiliza es (como debería ser) el número de descendientes por generación, en lugar del número de descendientes por unidad de tiempo absoluto, entonces existen evidentemente organismos biológicos que pueden reproducirse a ritmos mayores que los de las bacterias y que casi igualan los ritmos que Batten considera no realistas. Por ejemplo, una sola rana puede poner miles de huevos de una vez, cada uno de los cuales tiene el potencial de desarrollarse como adulto. De acuerdo, la mayoría de éstos normalmente no sobrevivirán debido a las limitaciones de recursos y a la depredación, pero entonces la mayoría de la ``descendencia'' de cada generación en un AG tampoco sobrevivirá.
Segundo, y más importante: un algoritmo genético trabajando para resolver un problema no pretende representar a un solo organismo. En cambio, un algoritmo genético es más análogo a una población completa de organismos -después de todo, son las poblaciones, y no los individuos, los que evolucionan. Por supuesto, es completamente plausible que una población tenga colectivamente cientos o miles de descendientes por generación. (El creacionista Walter ReMine comete este mismo error con respecto al programa ``weasel'' del Dr. Richard Dawkins. Vea este Mensaje del Mes para más información).
Además, dice Batten, la tasa de mutación es artificialmente alta en los AGs, mientras que los seres vivos tienen una maquinaria de comprobación de errores diseñada para limitar la tasa de mutación en aproximadamente 1 por cada 10.000 millones de par de bases (aunque esto es demasiado poco -la cifra real está más cerca de 1 por cada 1.000 millones. Ver Dawkins 1996[20], p. 124). Por supuesto, esto es cierto. Si los AGs mutasen a este ritmo, tardarían muchísimo en resolver problemas reales. Evidentemente, lo que debe considerarse relevante es la tasa de mutación relativa al tamaño del genoma. La tasa de mutación debe ser lo bastante alta para promover una cantidad suficiente de diversidad en la población sin acabar con los individuos. Un ser humano corriente posee entre una y cinco mutaciones; esto es perfectamente realista para la descendencia de un AG.
El argumento de Batten de que el genoma de un algoritmo genético ``es artificialmente pequeño y sólo realiza una cosa'' está completamente errado. En primer lugar, como ya hemos visto, no es cierto que un AG sólo realice una cosa; hay muchos ejemplos de algoritmos genéticos diseñados específicamente para optimizar muchos parámetros simultáneamente, a menudo muchos más parámetros de los que podría manejar un diseñador humano.
¿Y exactamente cómo cuantifica Batten lo de ``artificialmente pequeño''? Muchos algoritmos evolutivos, como el programa genético de John Koza, utilizan codificaciones de tamaño variable donde el tamaño de las soluciones candidatas pueden crecer arbitrariamente. Batten afirma que hasta los seres vivos más sencillos tienen mucha más información en su genoma que la que un AG haya producido nunca, pero si los organismos vivos actuales tienen genomas relativamente grandes es porque se ha ganado mucha complejidad en el curso de los miles de años de evolución. Como señala el artículo Probabilidad de abiogénesis, hay buenas razones para creer que los primeros organismos vivos eran mucho más sencillos que cualquier especie actual -las moléculas autorreplicadoras probablemente no tenían más de 30 o 40 subunidades, pudiendo quedar especificadas perfectamente con los 1.800 bits de información que Batten reconoce que ha generado al menos un AG. Asimismo, los algoritmos genéticos son una técnica muy nueva cuyo potencial completo todavía no ha sido explotado; las propias computadoras digitales sólo tienen unas pocas décadas, y como señala Koza (2003[42], p. 25), las técnicas de computación evolutiva han generado resultados cada vez más sustanciales y complejos durante los últimos 15 años, en sincronía con el rápido aumento de la potencia computacional, a menudo referida como la ``ley de Moore''. Al igual que la vida primigenia era muy sencilla comparada con la que vino después, es probable que los algoritmos genéticos actuales, a pesar de los impresionantes resultados que ya han producido, den origen a resultados mucho más importantes en el futuro.
Aparentemente, Batten no comprende cómo funcionan los algoritmos genéticos, y lo demuestra realizando este argumento. Afirma que, en la vida real, ``las mutaciones ocurren por todo el genoma, no sólo en un gen o sección que especifique un caracter dado''. Esto es cierto, pero cuando dice que lo mismo no es cierto para los AGs, se equivoca. Exactamente igual que en los seres vivos, los AGs deben escardar los genes perjudiciales al tiempo que seleccionan los beneficiosos.
Batten continua afirmando que ``el propio programa está protegido contra las mutaciones, sólo las secuencias objetivo mutan'', y si el programa mutara, fallaría poco después. Esta crítica, sin embargo, es irrelevante. No existe razón para que el programa que gobierna a un AG tenga que mutar. El programa no es parte del algoritmo genético; el programa es el que supervisa al algoritmo genético y produce las mutaciones en las soluciones candidatas, que son lo que el programador busca mejorar. El programa que ejecuta al AG no es análogo a la maquinaria reproductiva de un organismo, una comparación que trata de establecer Batten. En cambio, es análogo a las leyes naturales invariantes que gobiernan los entornos en los que viven y se reproducen los seres vivos, y no se espera que éstas cambien ni necesitan ``protegerse'' de ello.
Utilizando el argumento de la ``''
del creacionista de tipo tierra-vieja Michael Behe, Batten argumenta:
``Muchos caracteres biológicos requieren la presencia de muchos componentes
distintos, funcionando juntos, para que el caracter pueda existir'',
mientras que esto no ocurre en los AGs.
Sin embargo, es trivial demostrar que esta afirmación es falsa, ya
que los algoritmos genéticos han producido sistemas irreduciblemente
complejos. Por ejemplo, el circuito reconocedor de voz que evolucionó
el Dr. Adrian Thompson (Davidson 1997[19]) está compuesto
de 37 puertas lógicas. Cinco de ellas ni siquiera están conectadas
al resto del circuito, aunque hacen falta las 37 para que el circuito
funcione; si cualquiera de ellas se desconecta de la fuente de alimentación,
todo el sistema deja de funcionar. Esto se ajusta a la definición
de sistema complejo irreducible de Behe, y demuestra que un proceso
evolutivo puede producir cosas así.
Debe señalarse que este argumento es el mismo que el primero, simplemente
presentado en un lenguaje distinto, y por tanto la refuntación es
la misma. La complejidad irreducible no es un problema para la evolución,
esté la evolución ocurriendo en los seres vivos de la naturaleza o
en el silicio del procesador de una computadora.
Batten argumenta que los AGs ignoran asuntos como la poligenia (la
determinación de un caracter por múltiples genes), pleiotropía (un
gen que afecte a múltiples caracteres) y los genes dominantes y recesivos.
Sin embargo, ninguna de estas afirmaciones es cierta. Los AGs no ignoran
la poligenia y la pleiotropía: simplemente se permite que estas propiedades
surjan de manera natural en lugar de programarlas deliberadamente.
Es obvio que en cualquier sistema complejo interdependiente (es decir,
un sistema no lineal), la alteración o eliminación de una parte causará
una reacción en cadena por todo el sistema; por tanto, los AGs incorporan
de manera natural la poligenia y la pleiotropía. ``En la literatura
sobre algoritmos genéticos, la interacción entre parámetros se conoce
como epistasis (un término biológico para la interacción entre
genes). Cuando hay poca o ninguna epistasis, los algoritmos de búsqueda
mínima [es decir, los trepacolinas **-A.M.] rinden mejor.
Los algoritmos genéticos brillan cuando la epistasis es media o alta...''
(Haupt y Haupt 1998[34], p. 31, itálicas originales).
Igualmente, hay algunas implementaciones de algoritmos genéticos que
sí tienen cromosomas diploides y genes dominantes y recesivos (Goldberg
1989[29], p. 150; Mitchell 1996[47], p. 22). Sin
embargo, los que no lo son simplemente se parecen más a los organismos
haploides, como las bacterias, que a los organismos diploides, como
los seres humanos. Ya que las bacterias están entre los organismos
más exitosos de este planeta (para ciertas medidas), tales AGs siguen
siendo un buen modelo de la evolución.
Batten habla de la existencia de múltiples sistemas de lectura en
los genomas de algunos seres vivos, en los que las secuencias de ADN
codifican distintas proteínas funcionales cuando se leen en direcciones
distintas o con distintos desplazamientos de inicio. Afirma que ``crear
un AG para generar una codificación con información densa así parecería
imposible''.
Un reto así pide una respuesta, y aquí está: Soule y Ball 2001[61].
En este artículo, los autores presentan un algoritmo genético con
múltiples sistemas de lectura y codificación densa, permitiéndole
almacenar más información que el tamaño total de su genoma. Al igual
que los codones de tres nucleótidos especifican aminoácidos en los
genomas de los seres vivos, en este AG los codones eran cadenas binarias
de cinco dígitos (hay por lo tanto 25 o 64 codones posibles, el mismo
número de codones en los sistemas biológicos). Como los codones tenían
cinco dígitos de longitud, había cinco sistemas de lectura posibles.
La secuencia 11111 sirve como codon de ``comienzo'' y la 00000 como
codon de ``parada''; como el codon de comienzo y parada pueden aparecer
en cualquier lugar del genoma, la longitud de cada individuo era variable.
Las regiones del cromosoma que no caían entre pares comienzo-parada
eran ignoradas.
El AG se probó con cuatro problemas clásicos de maximización de funciones.
``Inicialmente, la mayoría de los bits no participan en ningún gen,
es decir, la mayor parte de un cromosoma no codifica nada. De nuevo,
esto es porque en los individuos iniciales aleatorios hay relativamente
pocos pares de codones comienzo-parada. Sin embargo, el número de
bits que no participan disminuye extremadamente rápido''. Durante
el curso de la ejecución, el AG puede incrementar la longitud efectiva
de su genoma introduciendo nuevos codones de comienzo en distintos
sistemas de lectura. Al final de la ejecución, ``la cantidad de superposiciones
es bastante alta. Muchos bits participan en varios genes (a menudo
en los cinco)''. En todos los problemas probados, el AG empezó, de
media, con 5 variables especificadas; al final de la ejecución, ese
número se había incrementado hasta una media de 25.
En los problemas de prueba, el AG con múltiples sistemas de lectura
produjo soluciones significativamente mejores que un AG estándar en
dos de los cuatro problemas, y mejores soluciones medias en los otros
dos. En uno de los problemas, el AG comprimió con éxito 625 bits de
información en un cromosoma de sólo 250 bits de longitud, utilizando
sistemas de lectura alternativos. Los autores tildan este comportamiento
de ``extremadamente sofisticado'' y concluyen que ``estos datos muestran
que un AG puede utilizar con éxito sistemas de lectura a pesar de
la complejidad añadida'' y que ``es claro que un AG puede introducir
nuevos`genes' mientras sea necesario para resolver un cierto problema,
incluso con las dificultades impuestas al utilizar codones de comienzo
y parada y genes superpuestos''.
Como muchas otras, esta objeción demuestra que Batten no comprende
bien lo que es un algoritmo genético y cómo funciona. Argumenta que
los AGs, al contrario que la evolución, tienen objetivos predeterminados
y especificados desde el principio, y como ejemplo de esto, ofrece
el programa ``weasel'' del Dr. Richard Dawkins.
Sin embargo, el programa weasel no es un verdadero algoritmo genético,
y no representa a los algoritmos genéticos, precisamente por esa razón.
No pretendía demostrar el poder de resolución de problemas de la evolución.
En cambio, su única intención era mostrar la diferencia entre la selección
de un solo paso (la infame frase del ``tornado pasando por una chatarrería
y produciendo un 747'') y la selección acumulativa de múltiples pasos.
Tenía un objetivo específico predeterminado de antemano. Los algoritmos
genéticos verdaderos, en cambio, no lo tienen.
En un sentido más general, los AGs sí tienen un objetivo, a saber,
encontrar una solución aceptable a un problema dado. En este mismo
sentido, la evolución también tiene un objetivo: producir organismos
que estén mejor adaptados a su entorno y por tanto experimenten un
mayor éxito reproductivo. Pero al igual que la evolución es un proceso
sin objetivos específicos, los AGs no especifican de antemano cómo
debe resolverse un problema dado. La función de aptitud solamente
se establece para evaluar lo bien que funciona una solución candidata,
sin especificar ninguna forma de funcionar particular y sin juzgar
de qué manera inventa. La solución en sí emerge luego mediante un
proceso de mutación y selección.
La siguiente afirmación de Batten demuestra claramente que no entiende
lo que es un algoritmo genético. Afirma que ``quizás si el programador
pudiera dar con un programa que permitiera que ocurriera cualquier
cosa y luego midiera la capacidad de supervivencia de los `organismos',
se estaría acercando a lo que se supone que hace la evolución'' -pero
así es exactamente como funcionan los algoritmos genéticos. Generan
aleagoriamente soluciones candidatas y provocan mutaciones aleatorias
sobre ellas durante muchas generaciones. No se especifica ninguna
configuración de antemano; como dice Batten, se permite que ocurra
cualquier cosa. Como escribe John Koza (2003[42], p. 37),
repitiendo misteriosamente las palabras de Batten: ``Una característica
importante... es que la selección [en la programación genética]
no es codiciosa. Los individuos que se sabe que son iferiores serán
seleccionados hasta un cierto grado. No se garantiza que se seleccionará
el mejor individuo de la población. Además, el peor individuo de la
población no será necesariamente excluído. Puede ocurrir cualquier
cosa y nada está garantizado''. (Una sección anterior trató este punto
concreto como uno de los puntos fuertes de los AGs). Y, sin embargo,
aplicando un filtro selectivo a estas candidatas mutadas aleatoriamente,
surgen soluciones eficientes, complejas y poderosas a problemas difíciles,
soluciones que no fueron diseñadas por ninguna inteligencia y que
a menudo pueden igualar o superar a las soluciones diseñadas por los
humanos. La alegre afirmación de Batten de que ``por supuesto eso
es imposible'' está en contradicción directa con la realidad.
La crítica final de Batten dice así: ``Para un AG particular, necesitamos
preguntar qué parte de la `información' generada por el programa está
en realidad especificada en el programa, en lugar de haber sido generada
de novo''. Acusa a los AGs de que a menudo no hacen más que encontrar
la mejor manera de que ciertos módulos interaccionen, cuendo los propios
módulos y las maneras que tienen de interactuar están especificadas
de antemano.
Es difícil saber qué hacer con este argumento. Cualquier problema
imaginable -los términos en una ecuación de cálculo, las moléculas
en una célula, los componentes de un motor, el capital en un mercado
financiero- pueden expresarse en términos de módulos que interactúan
de cierta manera. Si todo lo que se tiene son módulos sin especificar
que interactúan de maneras sin especificar, no hay problema que resolver.
¿Significa esto que la solución a ningún problema requiere la generación
de información nueva?
Respecto a la crítica de Batten sobre que la información contenida
en la solución esté especificada en el problema, la mejora manera
de mitigar sus preocupaciones es señalar la cantidad de ejemplos en
los que los AGs comienzan con poblaciones iniciales generadas aleatoriamente
que no están de ninguna manera diseñadas para ayudar al AG a resolver
el problema. Algunos de tales ejemplos son: Graham-Rowe 2004[31];
Davidson 1997[19]; Assion et al. 1998[6]; Giro,
Cyrillo y Galvão 2002[27]; Glen y Payne 1995[28];
Chryssolouris y Subramaniam 2001[16]; Williams, Crossley
y Lang 2001[64]; Robin et al. 2003[54]; Andreou,
Georgopoulos y Lokothanassis 2002[4]; Kewley y Embrechts
2002[39]; Rizki, Zmuda y Tamburino 2002[53]; y
especialmente Koza et al. 1999[41] y Koza et al. 2003[42],
que analiza el uso de programación genética para generar 36 inventos
competitivos con los humanos de diseños de circuitos analógicos, biología
molecular, algoritmia, diseño de controladores industriales y otros
campos, todos comenzando con poblaciones de candidatas iniciales generadas
aleatoriamente.
De acuerdo, algunos AGs sí comienzan con soluciones generadas inteligentemente
que luego intentan mejorar, pero esto es irrelevante: en esos casos
el objetivo no es sólo devolver la solución de entrada inicial, sino
mejorarla mediante la producción de información nueva. En cualquier
caso, aunque la situación inicial sea como la describe Batten, encontrar
la manera más eficiente mediante la que un cierto número de módulos
puede interactuar bajo un conjunto dado de limitaciones puede ser
una tarea nada trivial, cuya solución implique una cantidad considerable
de información nueva: el diseño de horarios en los aeropuertos internacionales,
por ejemplo, o las líneas de montaje de una fábrica, o la distribución
de barriles entre almacenes y destilerías. De nuevo, los AGs han demostrado
su efectividad a la hora de resolver problemas cuya complejidad abrumaría
a cualquier humano. A la luz de las múltiples innovaciones y soluciones
inesperadamente efectivas que ofrecen los AGs en muchos campos, la
afirmación de Batten de que ``la cantidad de información nueva generada
(por un AG) es normalmente bastante trivial'' suena verdaderamente
hueca.
El reciente libro ``No Free Lunch: Why Specified Complexity Cannot
Be Purchased Without Intelligence'' (``No dan almuerzos gratis: por
qué la complejidad específica no puede conseguirse sin inteligencia''),
del creacionista de tipo tierra-vieja, el Dr. William Dembski, está
dedicado principalmente al tema de los algoritmos evolutivos y de
cómo se relacionan con la evolución biológica. En particular, el libro
de Dembski trata de una cualidad elusiva que él llama ``complejidad
especificada'' que, según afirma él, está presente en gran abundancia
en los seres vivos, y que además los procesos evolutivos son incapaces
de generar, dejando como única alternativa el ``diseño'' a un ``diseñador
inteligente'' sin identificar, mediante mecanismos sin especificar.
Para apoyar su caso, Dembski apela a un tipo de teoremas matemáticos
conocidos como teoremas No Dan Almuerzos Gratis que, según él, demuestran
que los algoritmos evolutivos, de media, no lo hacen mejor que una
búsqueda ciega.
Richard Wein ha escrito una refutación excelente y detallada de Dembski,
titulada Not a Free Lunch But a
Box of Chocolates
(No un almuerzo gratis sino una caja de chocolates), y no reproduciré
sus ideas aquí. En cambio, me centraré en el capítulo 4 del libro
de Dembski, que trata en detalle de los algoritmos genéticos.
Dembski tiene un argumento principal en contra de los AGs, desarrollado
a fondo a lo largo de este capítulo. Aunque no niega que pueden producir
resultados impresionantes -de hecho, dice que hay algo ``extrañamente
persuasivo y casi mágico'' (p. 221) acerca del modo en el que los
AGs pueden encontrar soluciones diferentes a cualquier cosa diseñada
por seres humanos-, sostiene que su éxito es debido a la complejidad
específica ``pasada de tapadillo'' dentro de ellos por sus diseñadores
humanos y que posteriormente se manifiesta en las soluciones que producen.
``En otras palabras, toda la complejidad específica que obtenemos
de un algoritmo evolutivo debe aportarse primero en su construcción
y en la información que guía al algoritmo. Los algoritmos evolutivos,
por tanto, no generan o crean complejidad específica, sino que simplemente
aprovechan la complejidad especificada que ya existe'' (p. 270).
El primer problema evidente en el argumento de Dembski es éste. Aunque
su capítulo sobre algoritmos evolutivos ocupa aproximadamente 50 páginas,
las primeras 30 de ellas hablan de nada más que el algoritmo ``weasel''
del Dr. Richard Dawkins, el cual, como ya se ha dicho, no es un verdadero
algoritmo genético y no es representativo de los algoritmos genéticos.
Los otros dos ejemplos de Dembski -las antenas genéticas de alambre
doblado de Edward Altshuler y Derek Linden y las redes neuronales
que juegan a las damas de Kumar Chellapilla y David Fogel- se introducen
tan sólo en las últimas 10 páginas del capítulo y son tratadas en
tres páginas, en combinación. Esto es una seria deficiencia, considerando
que el programa ``weasel'' no es representativo de la mayor parte
del trabajo que se hace en el campo de la computación evolutiva; no
obstante, analizaré los argumentos de Dembski relacionados con él.
Respecto al programa ``weasel'', Dembski afirma que ``Dawkins y sus
compañeros darwinistas utilizan este ejemplo para ilustrar el poder
de los algoritmos evolutivos'' (p. 182) y, de nuevo, ``los darwinistas...
están encantados con el ejemplo CREO QUE SE PARECE A UNA COMADREJA
y lo consideran ilustrador del poder de los algoritmos evolutivos
para generar complejidad específica'' (p. 183). Esto es un
hombre de paja,
creación de Dembski (¡sobre todo porque el libro de Dawkins fue escrito
mucho antes de que Dembski acuñara ese término!). Esto es lo que Dawkins
dice realmente del propósito de su programa:
La selección de un solo paso es el proceso absurdamente improbable
atacado con frecuencia en la literatura creacionista, comparándolo
con un tornado pasando por una chatarrería y produciendo un avión
747, o una explosión en una imprenta produciendo un diccionario. La
selección acumulativa es lo que realmente utiliza la evolución. Utilizando
la selección de un solo paso para alcanzar un resultado funcional
de alguna complejidad significativa, hanría que esperar, de media,
muchas veces la edad actual del universo. Utilizando selección acumulativa,
por contra, se puede alcanzar ese mismo resultado en un periodo de
tiempo comparativamente muy corto. El objetivo del programa ``weasel''
de Dawkins era demostrar esta diferencia, y era el único objetivo
del programa. En una nota al pie de este capítulo, Dembski escribe:
``Es curioso cómo se recicla el ejemplo de Dawkins sin ninguna indicación
de las dificultades fundamentales que lo acompañan'' (p. 230), pero
tan sólo los conceptos erróneos de las mentes de los creacionistas
como Dembski y Batten, que atacan al programa ``weasel'' por no demostrar
algo que nunca pretendía demostrar, son los que dan lugar a estas
``dificultades''.
A diferencia de todos los ejemplos de algoritmo evolutivo tratados
en este ensayo, el programa ``weasel'' tiene ciertamente un resultado
especificado de antemano, y la calidad de las soluciones que genera
se juzga comparándola explicítamente con ese resultado especificado
de antemano. Por tanto, Dembski tiene toda la razón cuando dice que
el programa ``weasel'' no genera información nueva. No obstante, luego
realiza un salto gigantesco y completamente injustificado, al extrapolar
esta conclusión a todos los algoritmos evolutivos: ``Como única posibilidad
que puede alcanzar el algoritmo evolutivo de Dawkins, la secuencia
objetivo tiene de hecho una complejidad mínima... Por lo tanto,
los algoritmos evolutivos son incapaces de generar verdadera complejidad''
(p. 182). Hasta Dembski parece reconocer esto cuando escribe: ``...la
mayoría de los algoritmos evolutivos de la literatura están programados
para buscar en un espacio de soluciones posibles a un problema hasta
que encuentran una respuesta -no, como hace Dawkins, programando
explícitamente la respuesta de antemano'' (p. 182). Pero luego, habiendo
dado una razón perfectamente buena de por qué el programa ``weasel''
no es representativo de los AGs en conjunto, ¡prosigue inexplicablemente
realizando esa falaz generalización!
En realidad, el programa ``weasel'' es significativamente distinto
de la mayoría de los algoritmos genéticos, y por tanto el argumento
por analogía de Dembski no se sostiene. Los verdaderos algoritmos
evolutivos, como los ejemplos examinados en este ensayo, no buscan
simplemente un camino hacia soluciones ya descubiertas por otros métodos
-en cambio, se les presenta un problema para el que no se conoce
una solución óptima de antemano, y se les pide que descubran esa solución
por su cuenta. En realidad, si los algoritmos genéticos no pudieran
hacer más que redescubrir soluciones ya programadas dentro de ellos,
¿qué sentido tendría utilizarlos? Sería un ejercicio de redundancia.
Sin embargo, el amplio interés científico (y comercial) por los AGs
demuestra que hay mucha más sustancia en ellos que en el ejemplo bastante
trivial al que Dembski pretende reducir todo este campo.
Después de colocar y luego derribar este hombre de paja, Dembski avanza
hacia su siguiente línea de argumentación: que la complejida específica
exhibida por los resultados de los algoritmos evolutivos más representativos
ha sido ``pasada de tapadillo'' por los diseñadores dentro del algoritmo,
al igual que en el programa ``weasel''. ``Pero siempre encontramos
que cuando parece generarse complejidad específica de la nada, en
realidad ha sido cargada de antemano, pasada de tapadillo u ocultada
a la vista'' (p. 204). Dembski sugiere que el ``escondite'' más común
de la complejidad específica está en la función de aptitud del AG.
``Lo que ha hecho [el algoritmo evolutivo] es aprovecharse de
la complejidad específica inherente a la función de aptitud y la ha
utilizado para buscar y encontrar el objetivo...'' (p. 194).
Dembski prosigue argumentando que, antes de que un AE pueda buscar
una solución en un paisaje adaptativo dado, antes debe emplearse algún
mecanismo para seleccionar ese paisaje adaptativo de entre lo que
él llama un espacio de fases de todos los posibles paisajes adaptativos,
y que si ese mecanismo es también evolutivo, antes debe emplearse
algún otro mecanismo para seleccionar su función de aptitud de un
espacio de fases aún mayor, y así sucesivamente. Dembski concluye
que la única manera de detener esta regresión infinita es mediante
la inteligencia, la cual, según el, posee la irreducible y misteriosa
habilidad de seleccionar una función de aptitud de un espacio de fases
dado sin recurrir a espacios de fases de mayor orden. ``Sólo existe
un generador de complejidad específica conocido, y éste es la inteligencia''
(p. 207).
Dembski tiene razón cuando dice que la función de aptitud ``guía a
un algoritmo evolutivo hacia el objetivo'' (p. 192). Sin embargo,
no tiene razón cuando afirma que seleccionar la función de aptitud
correcta es un proceso que requiera la generación de más complejidad
específica de la que el propio AE produce. Como escribe Koza (1999[41],
p. 39), la función de aptitud le dice a un algoritmo evolutivo ``qué
hay que hacer'', no ``cómo hacerlo''. A diferencia del nada representativo
programa ``weasel'', normalmente la función de aptitud de un AE no
especifica ninguna forma particular que la solución deba adquirir,
y por tanto no se puede decir que contribuya a la ``complejidad específica''
de la solución evolucionada en ningún sentido.
Un ejemplo ilustrará la idea con mayor detalle. Dembski afirma que
en el experimento de las damas de Chellapilla y Fogel, su elección
de mantener constante el criterio de victoria entre juego y juego
``insertó una enorme cantidad de complejidad específica'' (p. 223).
Desde luego, es cierto que el producto final de este proceso exhibía
una gran cantidad de complejidad específica (se defina como se defina
ese término). Pero ¿es cierto que la medida de aptitud elegida contuviese
tanta complejidad específica? Esto es lo que dicen realmente Chellapilla
y Fogel:
Dembski afirma que para refutar su argumento, ``hace falta demostrar
que encontrar la información que guía a un algoritmo evolutivo hacia
un objetivo es sustancialmente más fácil que encontrar el objetivo
directamente mediante una búsqueda ciega'' (p. 204). Sostengo que
ése es precisamente el caso. Intuitivamente, no debe sorprender que
la función de aptitud contenga menos información que la solución evolucionada.
Ésta es precisamente la razón por la que los AGs han hallado un uso
tan amplio: es más fácil (requiere menos información) escribir una
función de aptitud que mida lo buena que es una solución que diseñar
una buena solución desde cero.
En términos más informales, consideremos los dos ejemplos de Dembski,
la antena genética de alambre doblado y la red neuronal jugadora de
damas evolucionada llamada Anaconda. Obtener una estrategia ganadora
requiere una gran cantidad de información detallada sobre el juego
de las damas (considere a Chinook y su enorme biblioteca de finales
de partida). Sin embargo, no hace falta una información igualmente
detallada para reconocer una estrategia así cuando se la ve: todo
lo que necesitamos observar es que esa estrategia vence consistentemente
a sus oponentes. De manera similar, una persona que no supiera nada
sobre cómo diseñar una antena que radie uniformemente en una región
hemisférica en un cierto rango de frecuencias, podría sin embargo
probar una antena así y verificar si funciona como se pretende. En
ambos casos, determinar lo que constituye una aptitud alta es mucho
más fácil (requiere menos información) que averiguar cómo conseguir
una aptitud alta.
De acuerdo, aunque requiera menos información escoger una función
de aptitud para un problema dado que resolver verdaderamente el problema
definido por esa función de aptitud, sí que hace falta algo de información
para especificar la función de aptitud en primer lugar, y es una cuestión
legítima preguntar de dónde viene esta información inicial. Dembski
todavía puede preguntar sobre el origen de la inteligencia humana
que nos permite decidir resolver un problema en lugar de otro, o sobre
el origen de las leyes naturales del cosmos que hacen posible que
la vida exista y florezca y que ocurra la evolución. Éstas son preguntas
válidas, y Dembski tiene derecho a pensar en ellas. Sin embargo, en
este punto - aparentemente inadvertido por el propio Dembski- se
ha alejado de su argumento inicial. Ya no está afirmando que la evolución
no pueda ocurrir; en cambio, esencialmente está preguntando por qué
vivimos en un universo en el que puede ocurrir la evolución. En otras
palabras, Dembski no parece darse cuenta de que la conclusión lógica
de su argumento es la evolución teísta. Es perfectamente compatible
con un Dios que (como muchos cristianos, incluyendo el biólogo evolutivo
Kenneth Miller, creen) utilizó la evolución como su herramienta creativa,
y creó el universo para hacer que fuera no sólo probable, sino seguro.
Concluiré aclarando algunos conceptos erróneos menores adicionales
del capítulo 4 de No Free Lunch. Para empezar, aunque Dembski, al
contrario que Batten, está claramente informado acerca del campo de
la optimización multiobjetivo, afirma erróneamente que ``hasta que
no se consiga alguna forma de univalencia, la optimización no puede
comenzar'' (p. 186). El análisis de los algoritmos genéticos multiobjetivo
de este ensayo muestran el error de esta afirmación. Quizá otras técnicas
de diseño tengan esta restricción, pero una de las virtudes de los
AGs es precisamente que pueden establecer contrapartidas y optimizar
varios objetivos mutuamente exclusivos simultáneamente, y luego un
supervisor humano puede elegir la solución que mejor consiga los resultados
esperados del grupo final de soluciones paretianas. No es necesario
ningún método para combinar múltiples criterios en uno.
Dembski también afirma que los AGs ``parecen menos expertos a la hora
de construír sistemas integrados que requieran de múltiples partes
para realizar funciones novedosas'' (p. 237). La gran cantidad de
ejemplos detallados en este ensayo (en particular, la utilización
de John Koza de la programación genética para diseñar circuitos analógicos
complejos) demuestran que esta afirmación también es falsa.
Finalmente, Dembski menciona que INFORMS, la organización profesional
de la comunidad de investigación de operaciones, le presta muy poca
atención a los AGs, y esto ``es una razón para ser escéptico acerca
del alcance y poder general de esta técnica'' (p. 237). Sin embargo,
sólo porque una sociedad científica particular no esté haciendo un
uso generalizado de los AGs no significa que esos usos no sean generalizados
en otros sitios o en general, y este ensayo ha procurado demostrar
que éste es ciertamente el caso. Las técnicas evolutivas han hallado
una amplia variedad de usos en prácticamente todos los campos de la
ciencia que merece la pena nombrar, además de muchas empresas del
sector comercial. Aquí hay una lista parcial:
Hasta los creacionistas encuentran imposible negar que la combinación
de la mutación y la selección natural puede producir adaptación. No
obstante, todavía siguen intentando justificar su rechazo a la evolución
dividiendo el proceso evolutivo en dos categorías -``microevolución''
y ``macroevolución''- y afirmando que sólo la segunda es controvertida,
y que cualquier cambio evolutivo que podemos observar es sólo un ejemplo
de la primera.
Veamos. La microevolución y la macroevolución son términos que tienen
significado para los biólogos; se definen, respectivamente, como evolución
por debajo del nivel de especies y evolución al nivel de especies
o por encima. Pero la diferencia crucial entre el modo en el que los
creacionistas utilizan estos términos y el modo en el que lo hacen
los científicos es que los científicos reconocen que los dos son fundamentalmente
el mismo proceso con los mismos mecanismos, tan sólo operando a diferentes
escalas. Sin embargo, los creacionistas están obligados a postular
algún tipo de brecha infranqueable que los separa, para poder negar
que los procesos de cambio y adaptación que vemos en la actualidad
puedan extrapolarse para producir toda la diversidad que vemos en
el mundo de los seres vivos.
No obstante, los algoritmos genéticos hacen que esta idea sea insostenible,
al demostrar la naturaleza sin junturas del proceso evolutivo. Consideremos,
por ejemplo, un problema que consista en programar un circuito para
que discrimine entre un tono de 1 kilohercio y un tono de 10 kilohercios,
y responda respectivamente con salidas uniformes de 0 y 5 voltios.
Digamos que tenemos una solución candidata que puede discriminar con
precisión entre los dos tonos, pero sus salidas no son lo bastante
uniformes como se requiere; producen pequeñas ondulaciones en lugar
del voltaje constante requerido. Supuestamente, de acuerdo con las
ideas creacionistas, cambiar este circuito de su estado presente a
la solución perfecta sería ``microevolución'', un cambio pequeño dentro
de las capacidades de la mutación y la selección. Pero, sin duda -argumentaría
un creacionista-, llegar a este mismo estado final desde una ordenación
inicial completamente aleatoria de componentes sería ``macroevolución'',
y estaría más allá del alcance de un proceso evolutivo. Sin embargo,
los algoritmos genéticos han sido capaces de conseguir ambas cosas:
evolucionar el sistema a partir de una ordenación aleatoria hasta
la solución casi perfecta y finalmente hasta la solución perfecta
y óptima. No surgió ninguna dificultad o brecha insalvable en ningún
punto del camino. En ningún momento hizo falta intervención humana
para montar un conjunto de componentes irreduciblemente complejo (a
pesar del hecho de que el producto final sí contiene tal cosa) o para
``guiar'' al sistema evolutivo a través de algún pico dificultoso.
El circuito evolucionó, sin la ayuda de ninguna orientación inteligente,
desde un estado completamente aleatorio y no funcional hasta un estado
rigurosamente complejo, eficiente y óptimo. ¿Cómo puede no ser esto
una demostración experimental convincente del poder de la evolución?
Se dice que la evolución cultural humana ha reemplazado a la biológica
-que nosotros, como especie, hemos llegado a un punto en el que somos
capaces de controlar conscientemente nuestra sociedad, nuestro entorno
y hasta nuestros genes al nivel suficiente para hacer que el proceso
evolutivo sea irrelevante. Se dice que los caprichos culturales de
nuestra cambiante sociedad son los que determinan la aptitud hoy en
día, en lugar de la marcha enormemente lenta, en comparación, de la
mutación genética y la selección natural. En cierto sentido, esto
puede ser perfectamente cierto.
Pero en otro sentido, nada podría estar más lejos de la verdad. La
evolución es un proceso de resolución de problemas cuyo poder sólo
comenzamos a comprender y explotar; a pesar de esto, ya está funcionando
por todas partes, moldeando nuestra tecnología y mejorando nuestras
vidas, y, en el futuro, estos usos no harán sino multiplicarse. Sin
un conocimiento detallado del proceso evolutivo no habrían sido posibles
ninguno de los incontables avances que le debemos a los algoritmos
genéticos. Aquí hay una lección que deben aprender los que niegan
el poder de la evolución y los que niegan que el conocimiento de ella
tenga beneficios prácticos. Por increíble que pueda parecer, la evolución
funciona. Como lo expresa el poeta Lord Byron: ``Es extraño pero cierto;
porque la verdad siempre es extraña, más extraña que la ficción.''
This document was generated using the
LaTeX2HTML translator Version 2002-2-1 (1.70)
Copyright © 1993, 1994, 1995, 1996,
Nikos Drakos,
Computer Based Learning Unit, University of Leeds.
The command line arguments were:
Traducción realizada por Gabriel Rodríguez Alberich.
Los AGs ignoran la poligenia, la pleiotropía y otras complejidades
genéticas
Los AGs no tienen múltiples sistemas de lectura
Los AGs tienen objetivos predeterminados
Los AGs no generan información nueva en realidad
William Dembski
Lo que importa es la diferencia entre el tiempo que tarda la selección
acumulativa, y el tiempo que tardaría la misma computadora,
funcionando absolutamente a la misma velocidad, en alcanzar la frase
objetivo si estuviera obligada a utilizar el otro procedimiento de
selección de un solo paso: más o menos un millón de millones
de millones de millones de millones de años'' (Dawkins 1996[20],
p. 49, itálicas originales).
En otras palabras, el programa ``weasel'' pretendía demostrar la diferencia
entre dos tipos distintos de selección: la selección de un solo paso,
en la que un resultado complejo está producido por puro azar en un
solo salto, y la selección acumulativa, en la que un resultado complejo
se construye poco a poco mediante un proceso de filtrado que preserva
preferentemente las mejoras. Nunca pretendió ser una simulación de
la evolución en su totalidad.
Para apreciar el nivel de juego que se había conseguido, puede ser
útil considerar el siguiente experimento mental. Suponga que le piden
jugar a un juego en un tablero de ocho por ocho casillas con colores
alternos. Hay 12 piezas en cada lado ordenadas de una cierta manera
antes de empezar el juego. Le dicen las reglas de movimiento de las
piezas (es decir, el movimiento diagonal, comer forzosamente, la promoción)
y que se pueden comer piezas. Sin embargo, no le dicen si comer piezas
es favorable o desfavorable (hay una versión de las damas llamada
`damas suicidas', en la que el objetivo es `perder' lo más rápidamente
posible) o incluso si constituye información relevante. Y lo que es
más importante, no le dicen cuál es el objetivo del juego. Usted simplente
realiza movimientos y en algún momento un observador externo declara
que el juego ha acabado. No obstante, no le proporcionan información
de si ha ganado, perdido o empatado. Los únicos datos que usted recibe
llegan tras un mínimo de cinco partidas y se ofrecen en la forma de
una puntuación global. Por tanto, no puede saber con certeza qué juegos
contribuyeron a la puntuación global ni en qué grado. Su reto consiste
en inducir los movimientos apropiados en cada partida tan sólo a partir
de esta burda información'' (Chellapilla y Fogel 2001[13],
p. 427).
La afirmación de Dembski de que esta medida de la aptitud insertó
una ``enorme'' cantidad de complejidad específica excede los límites
de lo absurdo. Si se le diera la misma información a un ser humano
que nunca hubiera oído hablar de las damas, y meses después volviéramos
para descubrir que se ha convertido en un jugador experto a nivel
internacional, ¿podemos concluír que se ha generado complejidad específica?
En contraste, dada la escasez de descubrimientos e investigación científica
estimulados por el diseño inteligente, Dembski no se encuentra en
posición de quejarse de la falta de aplicaciones prácticas. El diseño
inteligente es una hipótesis vacía, que no nos dice nada más que ``algún
diseñador hizo algo, de alguna manera, en algún momento, para provocar
este resultado''. En contraste, este ensayo ha demostrado con suerte
que la evolución es una estrategia de resolución de problemas llena
de aplicaciones prácticas.
Conclusión
Bibliografía
Ver también: Willihnganz, Alexis. ``Software that writes software.''
Salon, 10 de agosto de 1998. Disponible en línea.
Ver también: Bird, Jon y Paul Layzell. ``The evolved radio and its
implications for modelling the evolution of novel sensors.'' En Proceedings
of the 2002 Congress on Evolutionary Computation, p.1.836-1.841.
Ver también: Koza, John, Martin Keane y Matthew Streeter. ``Evolving
inventions.'' Scientific American, febrero de 2003, p. 52-59.
Ver también: Petit, Charles. ``Touched by nature: Putting evolution
to work on the assembly line.'' U.S. News and World Report,
vol.125, no.4, p.43-45 (27 de julio de 1998). Disponible en línea.
Ver también: ``Evolving business, with a Santa Fe Institute twist.''
SFI Bulletin, invierno de 1998. Disponible
en línea.
Ver también: Patch, Kimberly. ``Algorithm evolves more efficient engine.''
Technology Research News, junio/julio de 2000. Disponible
en
línea.
Ver también: ``Selecting better orbits for satellite constellations.''
Spaceflight Now, 18 de octubre de
2001. Disponible en línea.
``Darwinian selection of satellite orbits for military use.'' Space.com,
16 de octubre de 2001. Disponible en línea.
About this document ...
Algoritmos genéticos y computación evolutiva
Copyright © 1997, 1998, 1999,
Ross Moore,
Mathematics Department, Macquarie University, Sydney.
latex2html -split 0 -local_icons -up_url http://the-geek.org/docs algen.tex
El documento original se encuentra en la página web de
Talk.Origins.
Notas al pie
Gabriel Rodríguez Alberich
2004-10-22
![]()
![]()
![]()
